1+3[1] 4Dieses Tutorial dient als Dokumentation und Erweiterung zu dem, was in den Sitzungen in Bezug auf R erläutert wurde. Es soll dazu dienen, dass ihr die Inhalte nochmal in eigener Geschwindigkeit nacharbeiten könnt, zum Beispiel wenn es euch in der Sitzung zu schnell ging.
Am wichtigsten beim Programmieren-lernen und auch in der alltäglichen Anwendung ist, dass ihr es einfach mal ausprobiert und ein wenig experimentiert - ihr könnt nichts kaputt machen*. Bitte nutzt die hier angegeben Infos dann auch nur als Ausgangspunkt und informiert euch darüber hinaus gerne selbst. Eine riesige Stärke von R ist, dass es eine sehr grosse Community von Nutzerinnen und Nutzern gibt und ihr online zu allem und in allerlei Form Hilfe findet (Tutorials, Videos, etc.). Auch ChatGPT kann eine sehr grosse Hilfe sein. Entscheidet gerne selbst, welche Informationen euch persönlich am meisten helfen.
*eure Rohdaten solltet ihr trotzdem immer nochmal an einem zweiten Ort gespeichert haben.
19. November 2025
In dieser Sitzung werden in aller Kürze zunächst nochmal die Grundlagen von R erläutert. Das umfasst drei zentrale Elemente:
1) Ihr habt R und RStudio heruntergeladen und installiert
2) Ihr habt zentrale Elemente der Benutzeroberfläche kennengelernt
3) Ihr habt den Beispieldatensatz eingelesen und könnt einfach Befehle ausführen
R bezeichnet eine Programmiersprache, die im Hintergrund auf eurem Computer eingebunden wird. RStudio ist die Benutzeroberfläche, mit der ihr R bedient, also Daten einlest und bearbeitet, statistische Analysen durchführt, Grafiken erstellt und vieles mehr. Sowohl R als auch RStudio sind kostenlos. Für eine erfolgreiche Installation sind vier Schritte in der genannten Reihenfolge notwendig.
a) Download von R
Welchen Prozessor hat mein Mac?
b) Installation von R auf eurem Gerät.
c) Download von RStudio
d) Installation von RStudio
Ihr werdet in der Folge nur mit RStudio arbeiten. Die Installation von R war wichtig da RStudio - welches als Benutzeroberfläche dient - im Hintergrund auf R zugreift.
Die wichtigsten Elemente habe ich kurz in der Sitzung vorgestellt; ihr kennt diese natürlich auch aus den anderen Vorlesungen und Seminaren. Zur Wiederholung ist dieses Video-Tutorial hilfreich.
Um eure Analysen gemäss eurer Forschungsfrage durchführen zu können, müsst ihr die von euch gesammelten Daten auswerten (in dem Fall meist Zeitungstexte, Pressemitteilungen oder Beiträge auf sozialen Medien). Hierfür existieren Statistikprogramme wie R. Um das zu machen, müssen wir die Daten als erstes jedoch erst einmal in RStudio einlesen.
Für das Tutorial habe ich einen Beispieldatensatz erstellt, anhand dessen ihr die relevanten Schritte üben könnt. Ihr könnt aber auch direkt eure eigenen Daten bzw. eure eigenen Daten einlesen.
Den Beispieldatensatz könnt ihr hier herunterladen.
Als nächstes öffnet ihr RStudio und erstellt ein neues Script in RStudio (File -> New File -> R Script). Als erstes solltet ihr in dem neu geöffneten Script nun eine Überschrift einfügen, damit ihr wisst, um was es sich handelt. Es gibt zwei Arten, Eingaben in R zu machen. Normale Eingaben interpretiert R immer als Rechenoperationen oder Befehle, die ihr über Strg+Enter / Ctrl+Enter ausführen könnt (oder rechts oben im Editor-Fenster bei “Run”). Beispielsweise versteht R hier direkt, dass es sich um eine Rechnung handelt und wenn ihr die Teile markiert und STRG+Enter oder “Run” drückt, gibt RStudio in der Console unten links das entsprechende Ergebnis aus:
1+3[1] 4Wenn wir normalen Text eingeben (z.B. wie in Word), kommt es zu Fehlern, da dies keine eindeutigen Rechenoperationen oder Befehle für R sind und das Programm nicht erkennt, was es tun soll:
Hallo R, wie geht es dir?Error in parse(text = input): <text>:1:7: unerwartetes Symbol
1: Hallo R
^Um daher “normalen” Text in R einzugeben, müsst ihr dem Programm mitteilen, dass der Text nicht als Befehl gedacht ist. Das funktioniert, in dem ihr vor den entsprechenden Text ein Hashtag setzt (#).
# Dies ist nur ein Text, kein Rechenbefehl für RDiese Funktion ist sehr wichtig um Notizen an euch selbst oder andere Leserinnen im R-Code zu hinterlassen. Ihr solltet Kommentare fleissig nutzen, damit ihr oder andere in der Gruppe später noch nachvollziehen können, was ihr gemacht habt. Ihr werdet in der Folge sehen, wie man so etwas einsetzt. Zunächst aber zur Überschrift zurück:
# Einlesen von Beispieldatensatz und Reliabilität der Coder bestimmen.Speichert diese Datei nun am besten direkt und wählt dafür einen Speicherort und Namen für diese Datei aus (File -> Save as…) - das ist ganz ähnlich wie bei Word oder Excel. Für einen guten Überblick macht es ausserdem Sinn, sich eine gute Datei Struktur/Organisation zu überlegen. RStudio speichert seine Scripte mit der Dateiendung “.R”. Hieran erkennt ihr im Explorer/Finder, dass es sich um ein Script für R-Code handelt und entsprechend mit RStudio ausgeführt werden kann (äquivalent zu einem .docx-File bei Word).
Nun lest ihr den Beispieldatensatz in R ein. Das kann R aber nicht einfach so, sondern es benötigt ein Paket mit besonderen Befehlen, damit R weiss, wie es Excel Dateien korrekt in R einzulesen hat. Das benötigte Paket installiert und aktiviert ihr mit folgendem Code, den ihr einfach ein, zwei Zeilen unter eurer Überschrift in das R-Script einfügt. Beachtet auch, wie in diesem Beispiel Kommentare genutzt werden. Ihr könnt Kommentare in eine neue Zeile, aber auch direkt hinter einen Befehl schreiben. Sobald ein # kommt, ignoriert R den dahinterstehenden Text.
install.packages("readxl") # Paket zum Einlesen von Excel Dateien installieren
library(readxl) # Paket aktivierenEin Befehl funktioniert immer gleich. Der Befehl wird über den Namen aufgerufen. Oben sind es zwei Befehle. Einmal install.packages und einmal library. Danach folgt eine offene Klammer und in der Klammer wird geschrieben, auf was sich der Befehl beziehen soll. In beiden Fällen soll der Befehl auf das Paket readxl angewandt werden. Der erste Befehl sagt, dass das Paket installiert werden soll, der zweite Befehl, dass es aktiviert werden soll (bzw. der aktiven Bibliothek hinzugefügt wird). Eine geschlossene Klammer beendet den Befehl.
Die Installation sollte in dem Fall nur wenige Sekunden dauern und ein paar Warnungen in der Console ausgeben (das Fenster links unten). Sofern es keine Errors sind, können die Warnungen an dieser Stelle ignoriert werden.
Nun könnt ihr die Beispieldaten einlesen. Dafür müsst ihr die Exceldatei geschlossen haben und den Dateipfad zu der Exceldatei (also wo ihr data_example.xlsx gespeichert habt) kopieren. Ersetzt dann den untenstehenden fiktiven Dateipfad mit dem korrekten Dateipfad auf eurem Gerät. Bitte beachtet, dass ihr zum einlesen Slashes ( / ) benötigt. (Sollte es unter Windows nicht funktionieren, ersetzt den Slash mit zwei Backslashes ( \\ )).
data <- read_excel("C:/Users/Name/Documents/Studium/WS25/HypeHorror/data/data_example.xlsx")Ihr habt die Daten nun eingelesen und der Datentabelle den Namen data zugeordnet. Unter diesem Namen kann die Datentabelle wieder aufgerufen werden. Rechts oben in RStudio unter “Environment” seht ihr nun auch data aufgelistet. Per Doppelklick auf data im Environment könnt ihr die Tabelle ansehen - ähnlich wie bei Excel. Ihr könnt allerdings auf diese Art keine Änderungen an den Einträgen vornehmen.
Zwischenstand
Insgesamt solltet ihr nun folgenden Code in eurem R-Script haben. Dazu rechts im Environment der eingelesene Datensatz.
# Einlesen von Beispieldatensatz und Reliabilität der Coder bestimmen.
install.packages("readxl") # Paket zum Einlesen von Excel Dateien installieren
library(readxl) # Paket aktivieren
data <- read_excel("C:/Users/Name/Documents/Studium//WS25/HypeHorror/data/data_example.xlsx") # Einlesen der DatenTipp: Wenn man das erste Mal install.packages("") ausgeführt hat, kann man diesen Befehl auskommentieren (ein # an den Zeilenanfang), da dieses Paket nun auf dem Gerät installiert ist und man dies in Zukunft nicht mehr neu installieren muss und somit etwas Zeit spart. Es reicht dann, das benötigte Paket über den Befehl library() aufzurufen. (Es gibt noch eine elegantere Möglichkeit mit require(). Wen das interessiert, kann ja mal recherchieren).
Ihr könnt nun auch bereits mit den Daten spielen. Zum Beispiel könnt ihr per names(data) die Namen der Spalten des Datensatzes ausgeben lassen. Oder per table(data$outlet) eine Häufigkeitstabelle zu den Outlets in data.
names(data) [1] "nr" "link" "outlet" "date"
[5] "headline" "lead" "text" "article_type"
[9] "pics" "other_elements" "tone_trump_c1" "tone_trump_c2"
[13] "tone_trump_c3" table(data$outlet)
handel spon tages zon
3 5 3 4 19. November 2025
Nachdem wir im ersten Teil die Grundlagen aufgefrischt haben und uns vom Wissensstand alle auf dem gleichen Niveau befinden, können wir nun bereits ein wenig in die Anwendung eintauchen.
Das Lernziel für diesen Teil der Sitzung ist, grundlegende Methoden der deskriptiven (=beschreibenden) Statistik in R und RStudio kennenzulernen und auf eure Daten anwenden zu können. Ausserdem machen wir einen kurzen Abstecher in die Darstellung von Textdaten.
Wichtig hierbei: Wir arbeiten dafür weiter mit den bereits eingelesenen Beispieldaten, ihr könnt aber natürlich auch gerne eure eigenen Daten einlesen und schauen ob es auch damit klappt, das Prinzip ist dasselbe.
In einem ersten Schritt wollen wir grundlegende statistische Kennzahlen für unsere Daten ermitteln. Das ist in einem empirischen wissenschaftlichen Projekt fast immer der erste Schritt einer Analyse und dient dazu, eine grundlegendes Verständnis von den Daten zu bekommen: Was ist das Durchschnittsalter meiner Teilnehmenden, wie ist das Geschlechterverhältnis, wie sind die Bildungsabschlüsse verteilt, sind typische Fragen die bei einer Umfrage in einem ersten Schritt angeschaut werden. In eurem Kontext betreffen die grundlegenden, deskriptiven Fragen allerdings keine Teilnehmerinnen aus einer Umfrage, sondern eher eure Texte. Von Interesse sind hier z.B. Fragen wie: Wie lang sind meine Texte durchschnittlich, wie verteilen sich die Texte auf die verschiedenen Quellen, wie viele Texte enthalten ein bestimmtes Merkmal, etc.
Wendet bitte als nächstes einmal folgenden Befehl an. Dieser stellt sicher, dass die Tabelle in einem normalen sogenannten data.frame Format gespeichert ist und wir alle folgenden Operationen ohne Probleme anwenden können:
data <- as.data.frame(data)Wie in den meisten Tabellen sind die einzelnen Beobachtungen in Zeilen und die Spalten bilden die verschiedenen Variablen. Wenn ihr euch den Datensatz data anschaut, seht ihr, dass es hier z.B. die Variablen “nr”, “link”, “outlet”, “date”, usw. gibt. Um in R den Mittelwert einer Variable (= Spalte in unserem Fall) auszurechnen gibt es den Befehl mean(). Diesem Befehl müssen wir nun ein Argument bzw. eine Bezugsmenge zuweisen, für die der Befehl (in dem Fall der Mittelwert) ausgerechnet werden soll. Wir wollen nun als erstes den Mittelwert für die Spalte “pics” ausrechnen. Versuchen wir es mit der zunächst intuitiven Lösung, nämlich dem Spaltennamen:
mean(pics)Error: Objekt 'pics' nicht gefundenDas erzeugt einen Fehler, weil R das Objekt nicht kennt (beachte, es ist rechts oben im Environment selbst nicht aufgeführt). Da die Spalte “pics” Teil des grösseren Objekts data ist, müssen wir R auch mitteilen, dass “pics” in der Tabelle data zu finden ist. Das funktioniert mittel $, genauer mittels data$pics. Auf die Art wird R mitgeteilt, dass er im Objekt data schauen soll und dort die Spalte “pics” findet. Wir können das direkt testen:
data$pics [1] 2 1 4 1 1 0 1 0 1 7 1 1 1 1 1Ihr seht als Output den Inhalt der Spalte “pics” (ab und zu zu prüfen, ob die Werte mit der Tabelle data übereinstimmen ist immer sinnvoll. Damit wird vermieden, dass sich hier und da Fehler einschleichen, die man bei grösseren Datensätzen schnell übersehen kann). Auf die Art können wir den Inhalt aller Spalten aufrufen:
data$date [1] "2024-02-25 UTC" "2024-02-28 UTC" "2024-03-05 UTC" "2024-03-06 UTC"
[5] "2024-03-06 UTC" "2024-03-13 UTC" "2024-03-06 UTC" "2024-02-28 UTC"
[9] "2024-03-05 UTC" "2024-03-06 UTC" "2024-03-04 UTC" "2024-02-28 UTC"
[13] "2024-03-12 UTC" "2024-03-06 UTC" "2024-02-27 UTC"data$article_type [1] "agentur" "agentur" "normal" "agentur" "normal" "agentur" "normal"
[8] "agentur" "essay" "normal" "agentur" "agentur" "normal" "normal"
[15] "normal" Nice to know
Anstatt data$pics zu schreiben, könnt ihr auch data[,"pics"] schreiben. Das Ergebnis ist äquivalent. Der 2. Code ist etwas allgemeiner, da die eckigen Klammern ([]) der Code für eine Teilmenge sind. Hier wird entsprechend nach einer Teilmenge von data gefragt. In den Klammern wird dann auf Zeilen und Spalten verwiesen, von einem Komma getrennt. In unserem Beispiel bedeutet data[,"pics"] also, dass wir alle Zeilen auswählen (indem man nichts schreibt werden alle bestehenden Zeilen genommen), und dass wir die Spalte “pics” auswählen. Wenn ihr nur einzelne Zeilen auswählen wollt, könnt ihr das entsprechend vor dem Komma einfügen. Probiert es mal aus:
data[,"pics"] # hat das gleiche Ergebnis wie data$pics
data[1,"pics"] # hier wählen wir auch die Spalte "pics" aber nur die erste Zeile
data[1:5,] # Zeilen 1 bis 5 und alle Spalten
data[c(3,4,9),1] # Zeilen 3, 4 und 9 und nur Spalte 1 (anstatt dem Spaltennamen, kann man auch die Spaltennummer verwenden)
data[,c("pics","article_type")] # alle Zeilen aber 2 SpaltenIhr seht ausserdem, dass bei mehreren einzelnen Zeilen oder Spalten, diese Werte mit dem c()-Befehl kombiniert werden müssen. Damit wird eine Aufzählung markiert und R erkennt die Kommas richtig:
data[3,4,9, "pics"] Error in `[.data.frame`(data, 3, 4, 9, "pics"): unbenutztes Argument ("pics")Dieser Code ergibt einen Fehler, da R nur ein Komma erwartet, hier aber nun 3 Kommas sind und R nicht versteht, dass sich die ersten drei Werte alle noch auf die Zeilen berufen (alle Kommas sind für R gleich). Entsprechend müsst ihr markieren, dass die ersten drei Werte - in diesem Fall - eine Aufzählung von Zeilen darstellen:
data[c(3,4,9), c(8,9)] # Nur der Output von Zeilen 3, 4 und 9 und gleichzeitig nur Spalten 8 und 9 article_type pics
3 normal 4
4 agentur 1
9 essay 1Zurück zum Mittelwert, Median, etc.
Der Mittelwert für die Variable (= Spalte) “pics” kann entsprechend wie folgt ausgerechnet werden:
mean(data$pics) [1] 1.533333# oder
mean(data[,"pics"])[1] 1.533333Wir wissen nun, dass im Schnitt 1,53 Fotos pro Artikel enthalten sind. Nice. Genauso könnt ihr damit den Median oder beispielsweise die Standardabweichung einer Variable ausgeben lassen:
median(data$pics)[1] 1sd(data$pics)[1] 1.76743Das funktioniert aber nicht für die Spalte “article_type”, in welcher der Typ des Artikels codiert ist. Das liegt daran, dass für nominale Werte eine Angabe des Mittelwerts wenig Sinn ergibt (was ist der Mittelwert von “essay”, agentur” und “normal”?). Entsprechend bekommt ihr eine Fehlermeldung. Der Median hingegen lässt sich korrekterweise auch hier ausgeben.
mean(data$article_type)Warning in mean.default(data$article_type): Argument ist weder numerisch noch
boolesch: gebe NA zurück[1] NAmedian(data$article_type)[1] "essay"Eine weiterer hilfreicher Befehl ist, die Häufigkeit der unterschiedlichen Ausprägungen einer Variable anzeigen zu lassen. Hierfür ist der Befehl table() gedacht. Ihr seht schnell wie er funktioniert und was er als Resultat ausgibt:
table(data$article_type)
agentur essay normal
7 1 7 Die relativen Häufigkeiten bekommt hier mit folgender Erweiterung:
prop.table(table(data$article_type))
agentur essay normal
0.46666667 0.06666667 0.46666667 Hier fällt auf, dass die ausführliche Angabe der Nachkommastellen etwas unnötig ist. Das kann man vermeiden, indem man Ergebnisse in R auf die gewünschte Nachkommastelle rundet. Das funktioniert mit dem Befehl round(code,x), wobei code der Code oder Befehl ist, dessen Ergebnis ihr runden wollt und x die Anzahl an Ziffern ist, auf die ihr nach dem Komma runden wollt. Zum Beispiel:
round(prop.table(table(data$article_type)),2)
agentur essay normal
0.47 0.07 0.47 Mittelwerte für Teilmengen einer Variable
Oft ist es aber so, dass ihr nicht am Gesamtmittelwert interessiert seid, sondern zwischen Texttypen oder Quellen unterscheiden wollt. Wenn wir z.B. den Mittelwert an Bildern pro Artikel (oder ein sonstiges Merkmal, das ihr identifiziert habt, z.B. Häufigkeit bestimmter Frames), getrennt nach Medienhaus bekommen wollen, müssen wir die Daten erst entsprechend aufsplitten.
Das geht auf zwei Arten. Ein Weg ist, den Datensatz in die Teile aufzusplitten, für die ihr jeweils den Mittelwert berechnen wollt. Anschliessend könnt ihr für jede Teilmenge den Mittelwert wie gewohnt berechnen. Dieser Weg hat ein zwei verschiedene Schritte, ist aber sehr intuitiv.
Für einen Überblick lasse ich ich mir zunächst aber nochmal die Namen der Medienhäuser geben:
data$outlet #listet alle auf [1] "spon" "spon" "spon" "spon" "spon" "zon" "zon" "zon"
[9] "zon" "handel" "handel" "handel" "tages" "tages" "tages" unique(data$outlet) # listet jeden Namen nur einmal auf[1] "spon" "zon" "handel" "tages" Nun erstelle ich eine erstelle eine Teilmenge der Haupttabelle data, getrennt nach den jeweiligen Medienhäusern. Das muss ich allerdings für jedes Medienhaus einzeln tun. Und zwar mit folgender Logik. Von meinem Datensatz data, nimm aus der Spalte “outlet” (also data$outlet) nur die Werte, die genau (==) “spon” entsprechen und weise sie einem neuen Objekt zu (in dem Fall spon_data). Entsprechend für die anderen Outlets.
spon_data <- subset(data, data$outlet == "spon")
zon_data <- subset(data, data$outlet == "zon")
handel_data <- subset(data, data$outlet == "handel")
tages_data <- subset(data, data$outlet == "tages")Ihr seht ausserdem, dass wir hier ein == anstatt einem einfachen “=” nutzen. Das hängt damit zusammen, dass “=” bereits vergeben ist und wie “<-” eine Zuweisung von Werten bedeutet. Unser herkömmliches Verständnis von “=” wird in R am ehesten durch == umgesetzt.
Wenn wir das gemacht haben, erscheinen rechts oben vier neue Objekte mit den eben vergebenen Namen. Diese können wir uns wie gewohnt anschauen und wir erkennen, dass es sich bei den neuen Tabellen um die gewünschten Teilmengen des Hauptdatensatzes handelt. Für jede dieser Teiltabellen können wir wie gewohnt den Mittelwert berechnen - unter Angabe des neuen Namens des jeweiligen Datensatzes:
mean(spon_data$pics)[1] 1.8mean(zon_data$pics)[1] 0.5mean(handel_data$pics)[1] 3mean(tages_data$pics)[1] 1Deutlich schneller, aber von den Schritten auf den ersten Blick nicht ganz so intuitiv ist folgender Code. Dieser wirft mit nur einer Zeile Code die Mittelwerte für alle vier Outlets aus:
#install.packages("dplyr") #Hastag am Anfang entfernen, falls ihr "dplyr" das erste Mal installiert
library(dplyr)
data %>% group_by(outlet) %>% summarise(mean_value = mean(pics))# A tibble: 4 × 2
outlet mean_value
<chr> <dbl>
1 handel 3
2 spon 1.8
3 tages 1
4 zon 0.5Nachdem ihr das Paket dplyr installiert und aktiviert habt, seht ihr, dass dieser Code das gleiche Resultat wie die Schritte oben hat - allerdings in nur einer Zeile Code. Ein wichtiges Take-Away hieraus: In R führen oft verschiedene Wege zum Ziel.
Eine kurze intuitive Erläuterung dieser Codezeile:
Zunächst nehmt ihr ganz normal data und verweist den Datensatz per %>% - dem sogenannten Pipe-Operator - an den nächsten Befehl. Das ist hier group_by(outlet) . Dieser Befehl erstellt für die zugewiesene Variable (hier “outlet”) die entsprechenden in ihr enthaltenen Gruppen. Wir wissen, dass “outlet” vier Ausprägungen, also Gruppen hat. Dieses Ergebnis, also alle vier Gruppen, werden dann mit einem erneuten Pipe-Operator an den nächsten Befehl weitergereicht: summarise(mean_value = mean(pics)). Der summarise()-Befehl bedeutet, dass für alle an ihn übergebenen Daten, in dem Fall die vier Outlets, die Befehle in seiner () angewendet werden. Hier ist das entsprechend mean_value = mean(pics). “mean_value” ist dabei ein von uns gewählter Name. Probiert es mal aus und ersetzt “mean_value” oben mit “hokuspokus”. Ihr werdet sehen, dass lediglich der Name der Spalte im Ergebnis geändert ist. “mean_value” ist damit lediglich der Name, unter welchem die Ergebnisse des folgenden Befehls gespeichert werden: mean(pics. Hier handelt es sich um den bereits bekannten Befehl für Mittelwert und diesem wird hier die Spalte “pics” anvertraut. Da heisst, mean() rechnet für die ihm überstellten Daten (also unsere vier Outlets) den Mittelwert der Spalte “pics” aus und speichert das Ergebnis unter “mean_value” (oder “hokuspokus”) ab.
Zusammengefasst erledigt der Code hier in einer Zeile, wofür wir davor 8 Zeilen benötigt haben. Ausserdem müsst ihr vor die einzelnen Zeilen (hier: “outlets” und “pics”) nicht jedes Mal erneut den Datensatz schreiben (also z.B.: data$outlets), weil R durch den allerersten Befehl der Zeile (data %>%) versteht, dass ihr euch nur auf diesen Datensatz bezieht. Das macht den Code etwas übersichtlicher und kürzer.
Wie immer, könnt ihr das Ergebnis auch einem neuen Objekt zuweisen, um es später wieder leicht aufrufen zu können:
outlet_means <- data %>% group_by(outlet) %>% summarise(mean_value = mean(pics))
outlet_means# A tibble: 4 × 2
outlet mean_value
<chr> <dbl>
1 handel 3
2 spon 1.8
3 tages 1
4 zon 0.5Hier werden die Mittelwerte der vier Outlets nun in der neuen Tabelle outlet_means gespeichert. Ihr seht, das dieses Objekt nun rechts oben aufgelistet ist.
Auf die gleiche Weise können wir nun auch die Anzahl an Bildern je Artikeltyp (= article_type) ausrechnen:
type_means <- data %>% group_by(article_type) %>% summarise(type_mean = mean(pics))Diese Ergebnisse erlauben nun schon erste interpretative Erkentnisse. Zum Beispiel benutzt das Handelsblatt in unserem kleinen Beispiel offenbar am häufigsten Bilder und Zeit Online am wenigsten. Genauso finden wir in Agenturmeldungen weniger Bilder als in normalen Nachrichtenbeiträgen.
Die bisherigen Ausführungen werden für alle von euch relevant sein, haben aber ansich nur indirekt etwas mit Texten zu tun, nämlich insoweit, dass die Daten Texte beschreiben; selbst aber keine wirklichen Textdaten sind. Man kann in R aber auch mit Texten selbst arbeiten und diese analysieren. Beispielsweise kann man vergleichen, welche Länge verschiedene Überschriften haben und den Mittelwert davon berechnen. Das geht wie folgt:
nchar(data$headline) # Anzahl Zeichen der jeweiligen Headlines mean(nchar(data$headline)) # Mittelwert davon [1] 46 66 42 62 30 70 41 49 27 41 60 48 18 30 21Wenn wir die Anzahl der Wörter in einem Text erfassen wollen, müssen wir zunächst wieder ein Zusatzpaket installieren, da R von Haus aus hierfür keine Befehle kennt.
install.packages("stringr")
library(stringr)data$word_count <- str_count(data$text, "\\S+")
# Zählt die Anzahl der Wörter in der Spalte "text" und
# speichert das Ergebnis in einer neuen Spalte "word_count" ab.Wenn ihr den Datensatz nun anschaut, seht ihr das Ergebnis, also die Anzahl der Wörter der jeweiligen Texte, in einer neuen Spalte am Ende des Datensatzes. Das waren jetzt nur sehr einfache Textoperationen. Mit dem Paket “stringr” könnt ihr allerlei nützliche und auch komplexere Operationen durchführen.
Wichtig: Es ist sehr wichtig, nach jedem Befehl die korrekte Ausführung zu überprüfen, indem man sich das Resultat anschaut und auf Plausibilität prüft. Andernfalls können sich Fehler einschleichen und die Analyse am Ende falsch sein. Den Fehler dann zu finden (sofern man ihn überhaupt bemerkt), ist deutlich mühsamer, als während der Ausführung aufmerksam zu sein.
In diesem Fall erscheint das Ergebnis plausibel. Per Augenmass ist erkennbar, dass Text 5 länger ist als die anderen Texte und Text 1 und 4 am kürzesten sind. Manchmal reicht Augenmass allerdings nicht aus um ein Ergebnis zu prüfen. In dem Fall sollte geschaut werden, ob ihr mit anderen Methoden auf das identische Ergebnis kommt. Hier wollen wir die Wörter natürlich nicht manuell nachzählen, aber wir können beispielsweise einen der Texte in Word kopieren und schauen, ob Word die gleiche Anzahl für einen Text ausgibt. Damit testen wir in gewisserweise die Validität des Befehls in R, eine Thematik, die uns in einer späteren Sitzung noch begegnet.
Neben schlichten Kennzahlen bieten sich für bestimmte Daten aber auch grafische Darstellungen an. Wir lernen hier nur die absoluten Basics. R ist sehr vielseitig und mächtig und lässt auch abenteuerlichste und massgeschneiderte Darstellungen zu. Schaut zum Beispiel hier für einige wunderschöne Beispiele. In vielen Fällen erfordert das allerdings fortgeschrittene Kentnisse und geht damit über die Kurztutorials dieses Kurses hinaus. Wer sich aber dafür interessiert findet unter dem Stichwort ggplot2 (was ein eigenes Paket für R ist) eine ganzes Universum an Möglichkeiten, allerlei Daten auf alle erdenklichen Arten grafisch aufzubereiten.
Wir bleiben hier allerdings bei den Basics, die bereits recht hilfreich sein können:
pie(data$pics) # Tortendiagramm
barplot(data$pics) # Balkendiagramm
Beide Darstellungen sind nicht sonderlich hilfreich. Häufig ist eine der zentralen Aufgaben der visuellen Darstellung, sich zu überlegen, ob die Daten schon im richtigen Format für eine sinnvolle Darstellungen sind. Das kann mühsam sein, insbesondere da R in Fällen wie oben keinen Fehler ausgibt. Die Darstellungen bzw. Befehle sind nämlich formal nicht falsch (z.B. seitens der Syntax), sie sind allerdings inhaltlich nicht sinnvoll bzw. haben schlicht keinen Mehrwert.
Welche der folgenden Darstellungen ist sinnvoll?
dotchart(table(data$pics))Warning in dotchart(table(data$pics)): 'x' ist weder Vektor noch Matrix: nutze
as.numeric(x)
plot(table(data$pics))
pie(table(data$pics))
Sehr oft ist eine Darstellung der Rohdaten alleine nicht sinnvoll oder nicht gewünscht, sondern gewisse Bearbeitungsschritte sind notwendig, um die Daten in eine Form zu bringen, die finale Analyse durchführen zu können. Tatsächlich machen solche Datenbearbeitungsschritte meist den Grossteil der Analysearbeit in empirischen Projekten aus. Auch wir haben das rudimentär schon gemacht, nämlich als wir den Mittelwert nach Gruppen getrennt aufgeschlüsselt haben. Auch hier profitieren wir davon und können unsere Ergebnisse grafisch darstellen:
barplot(outlet_means$mean_value)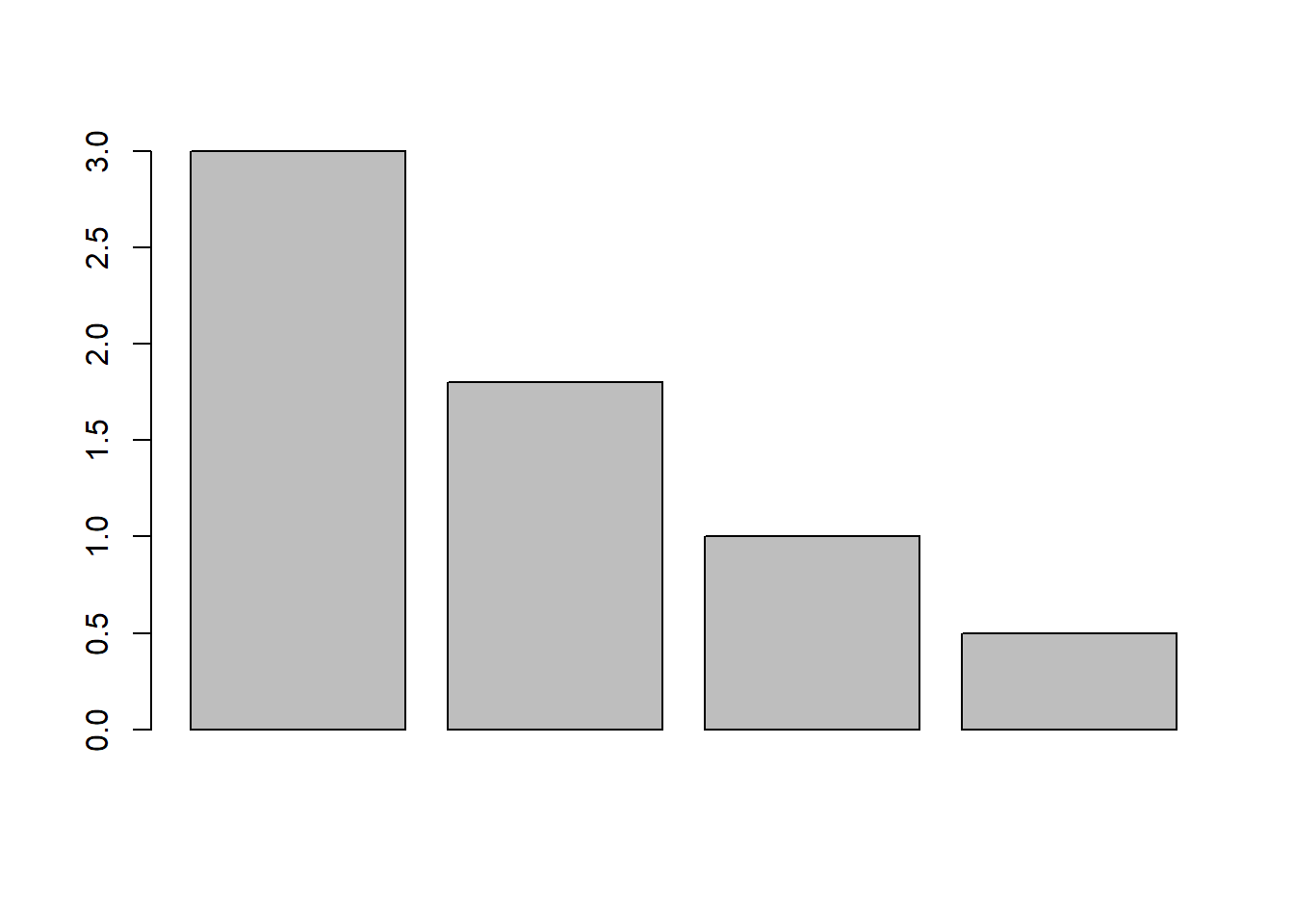
Diese Darstellung ist allerdings noch arg trostlos und auch unvollständig. Mit weiteren Argumenten können der Darstellung aber noch sinnvolle und notwendige Elemente hinzugefügt werden:
barplot(outlet_means$mean_value, names.arg = outlet_means$outlet, xlab = "Medienhäuser", ylab = "Durchschnittle Anzahl Bilder", col = heat.colors(4))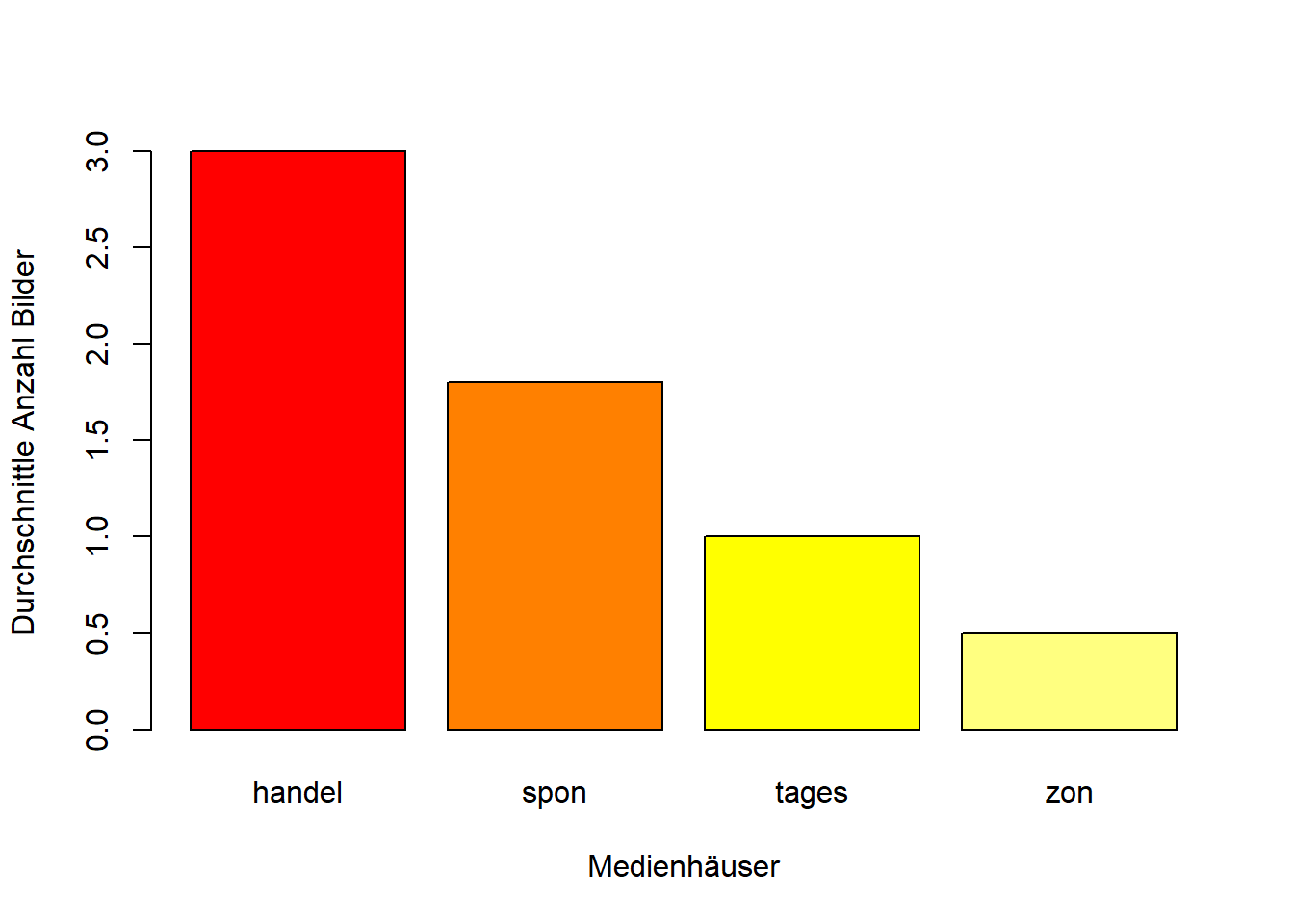
Erinnerung Mit dem Befehl ? hier z.B.: ?barplot() könnt ihr die Hilfe für den jeweiligen Befehl aufrufen. Hier seht ihr, welche Argumente grundsätzlich für den jeweiligen Befehl möglich sind und in welcher Art und Wiese diese in dem Befehl aufgeschrieben werden müssen.
Schaut mal in die Hilfe und versucht eigenständig, einen Gesamttitel für das Balkendiagramm einzufügen.
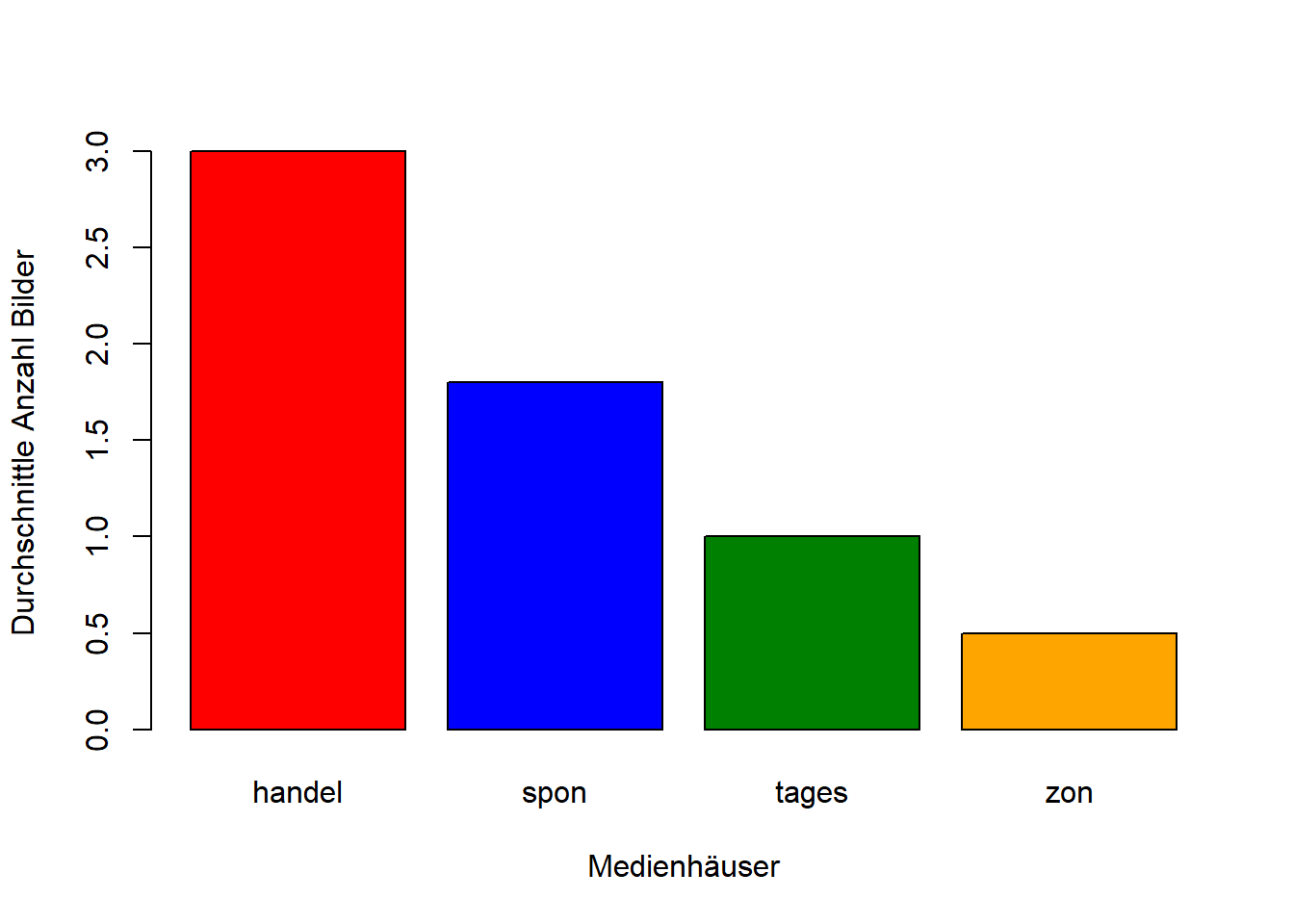
Die Farben können übrigens auch von euch frei gewählt werden, z.B. in dem ihr das aktuelle Argument für Farben durch folgende Codes ersetzt (siehe HTML-Farbcode für feinstufige Farbauswahl):
barplot(outlet_means$mean_value, names.arg = outlet_means$outlet, xlab = "Medienhäuser", ylab = "Durchschnittle Anzahl Bilder", col = colors <- c("#FF0000", "#0000FF", "#008000","#FFA500")
)
Genauso können für eine bessere Verständlichkeit auch die Namen der Medienhäuser in der entsprechenden Spalte noch ausgeschrieben werden. Dann werden sie in der Darstellung auch entsprechend angezeigt:
outlet_means$outlet <- c("Handelsblatt","Spiegel Online","Tagesschau","Zeit Online") #Achtung, auf richtige Reihenfolge achten!
barplot(outlet_means$mean_value, names.arg = outlet_means$outlet, xlab = "Medienhäuser", ylab = "Durchschnittle Anzahl Bilder", col = colors <- "lightblue")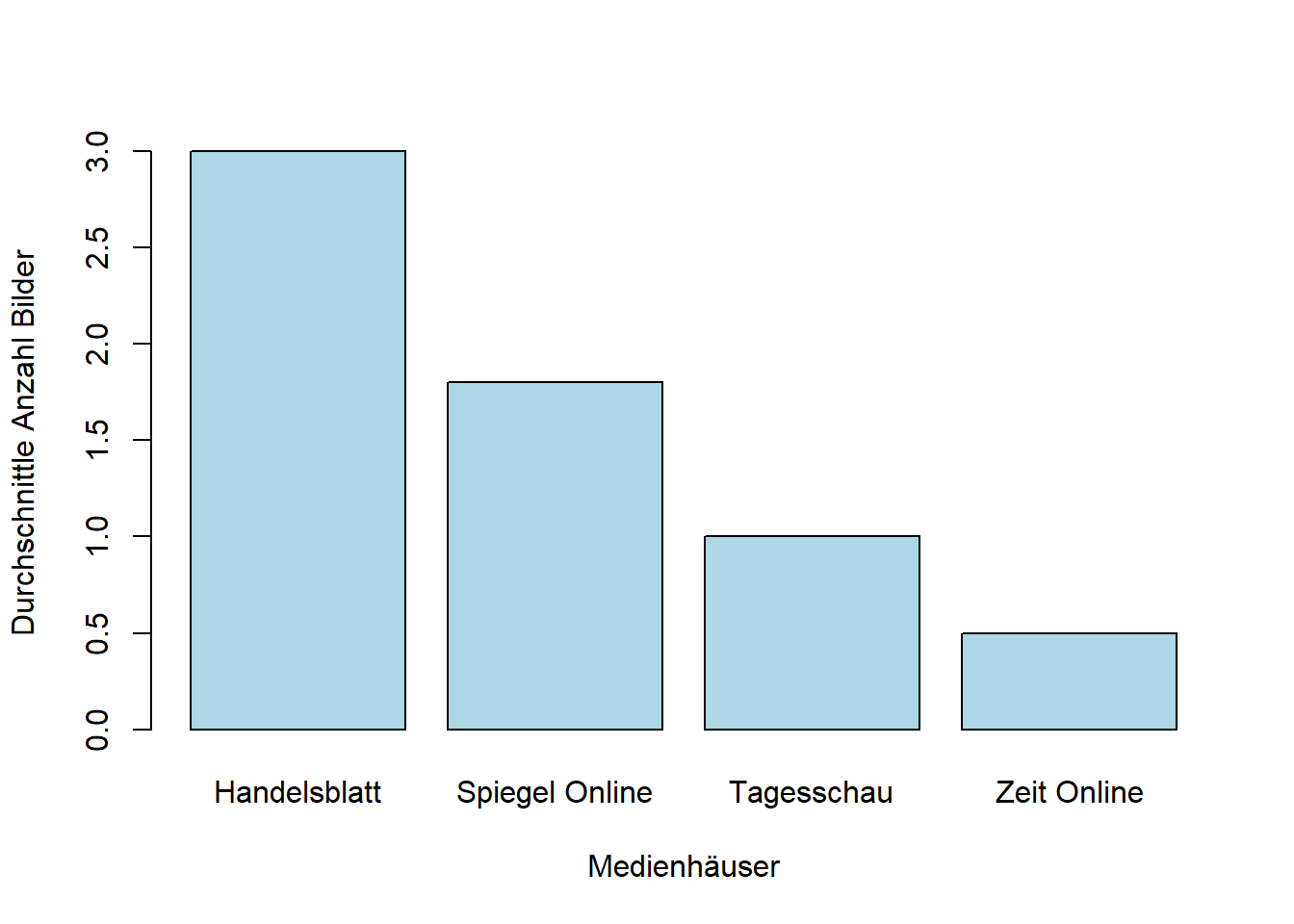
Die Masszahlen und Darstellungsformen soweit waren sehr allgemein und auf alle Arten von Daten anwendbar. Zuletzt wollen wir noch eine Darstellungsform kennen lernen, die spezifisch für Textdaten anwendbar ist: Wortwolken
Hierfür ist es hilfreich, ein Paket (bzw. zwei) zu installieren, welches spezifisch für die Arbeit mit Textdaten geschaffen wurde:
install.packages(c("quanteda", "quanteda.textplots"))Paket 'quanteda' erfolgreich ausgepackt und MD5 Summen abgeglichenPaket 'quanteda.textplots' erfolgreich ausgepackt und MD5 Summen abgeglichen
Die heruntergeladenen Binärpakete sind in
C:\Users\Michael\AppData\Local\Temp\RtmpGOWpUc\downloaded_packageslibrary(quanteda)
library(quanteda.textplots)Die Autoren dieses Pakets haben uns viel Arbeit erspart und machen es uns einfach: Um nun eine Wortwolke zu erzeugen sind nur drei einfache Schritte notwendig. Ihre Bedeutung habe ich in den Kommentaren im Code erläutert:
text_tokens <- tokens(data$text) #die Texte der Artikel werden in einzelne Wörter aufgetrennt
text_matrix <- dfm(text_tokens) #die aufgetrennten Wörter werden nun in einer speziellen Matrixform gespeichert (Document-Feature-Matrix DFM)
textplot_wordcloud(text_matrix) # aus dieser DFM wird eine Wortwolke kreiert
Das ist schon ganz cool, aber auch ein wenig unübersichtlich. Wir wollen die Wolke nun auf die 50 häufigsten Wörter (hier: tokens) limitieren Das ist durch quanteda einfach möglich, da es im Befehl für die Wordcloud ein Argument gibt, die Grösse zu beschränken (siehe ?textplot_wordcloud()):
textplot_wordcloud(text_matrix, max_words = 50)
Nun ist diese Darstellung allerdings übersichtlich, aber noch nicht sehr hilfreich, da wir lauter inhaltslose Füllwörter wie “der”, “die”, “und”, etc. haben. Solche inhaltslose Füllwörter werden als “Stopwords” bezeichnet. Für verschiedene Sprachen sind hier in dem Paket quanteda bereits Listen hinterlegt, die festlegen welche Wörter als solche stopwords zählen (wir können solche Listen auch selbst definieren). Diese existierende Liste können wir uns auch anzeigen lassen:
stopwords("german") [1] "aber" "alle" "allem" "allen" "aller" "alles"
[7] "als" "also" "am" "an" "ander" "andere"
[13] "anderem" "anderen" "anderer" "anderes" "anderm" "andern"
[19] "anderr" "anders" "auch" "auf" "aus" "bei"
[25] "bin" "bis" "bist" "da" "damit" "dann"
[31] "der" "den" "des" "dem" "die" "das"
[37] "daß" "derselbe" "derselben" "denselben" "desselben" "demselben"
[43] "dieselbe" "dieselben" "dasselbe" "dazu" "dein" "deine"
[49] "deinem" "deinen" "deiner" "deines" "denn" "derer"
[55] "dessen" "dich" "dir" "du" "dies" "diese"
[61] "diesem" "diesen" "dieser" "dieses" "doch" "dort"
[67] "durch" "ein" "eine" "einem" "einen" "einer"
[73] "eines" "einig" "einige" "einigem" "einigen" "einiger"
[79] "einiges" "einmal" "er" "ihn" "ihm" "es"
[85] "etwas" "euer" "eure" "eurem" "euren" "eurer"
[91] "eures" "für" "gegen" "gewesen" "hab" "habe"
[97] "haben" "hat" "hatte" "hatten" "hier" "hin"
[103] "hinter" "ich" "mich" "mir" "ihr" "ihre"
[109] "ihrem" "ihren" "ihrer" "ihres" "euch" "im"
[115] "in" "indem" "ins" "ist" "jede" "jedem"
[121] "jeden" "jeder" "jedes" "jene" "jenem" "jenen"
[127] "jener" "jenes" "jetzt" "kann" "kein" "keine"
[133] "keinem" "keinen" "keiner" "keines" "können" "könnte"
[139] "machen" "man" "manche" "manchem" "manchen" "mancher"
[145] "manches" "mein" "meine" "meinem" "meinen" "meiner"
[151] "meines" "mit" "muss" "musste" "nach" "nicht"
[157] "nichts" "noch" "nun" "nur" "ob" "oder"
[163] "ohne" "sehr" "sein" "seine" "seinem" "seinen"
[169] "seiner" "seines" "selbst" "sich" "sie" "ihnen"
[175] "sind" "so" "solche" "solchem" "solchen" "solcher"
[181] "solches" "soll" "sollte" "sondern" "sonst" "über"
[187] "um" "und" "uns" "unse" "unsem" "unsen"
[193] "unser" "unses" "unter" "viel" "vom" "von"
[199] "vor" "während" "war" "waren" "warst" "was"
[205] "weg" "weil" "weiter" "welche" "welchem" "welchen"
[211] "welcher" "welches" "wenn" "werde" "werden" "wie"
[217] "wieder" "will" "wir" "wird" "wirst" "wo"
[223] "wollen" "wollte" "würde" "würden" "zu" "zum"
[229] "zur" "zwar" "zwischen" Diese Wöter wollen wir nun aus unseren Texten entfernen. Das geht wie folgt. Wir fangen dabei wieder bei unseren Ausgangsdaten an und der Code ist fast identisch zu davor. Mit einem kleinen Zusatz. Schau gerne ob du ihn entdeckst und erraten kannst, was dort passiert und auch, was ich sonst noch geändert habe und warum:
text_tokens <- tokens(data$text, remove_punct = TRUE)
text_tokens <- tokens_remove(text_tokens, pattern = stopwords("german"))
text_matrix <- dfm(text_tokens)
textplot_wordcloud(text_matrix, max_words = 50)
Spannend wäre auch, als nächstes zu schauen, ob sich die häufigsten Wörter in den Texten je nach Medienhaus unterscheiden. Hat jemand eine Idee wie man das mit den Methoden, die wir bisher kennen gelernt haben grafisch analysieren könnte?
Ich kann euch sehr empfehlen, euch mal die Beispielseite von quanteda anzuschauen. Abseits der Wortwolke, sind hier noch weitere wirklich hilfreiche Darstellungsformen gut verständlich aufbereitet. Insgesondere die Frequency Plots, siehe hier, könnten für die ein oder andere Auswertung möglicherweise interessant sein (dort wird dann auch auf das oben bereits kurz erwähnte Paket für grafische Darstellungen ggplot2 zurückgegriffen).
Nice to know:
Die Art und Weise wie in der Textverarbeitung Texte oft gespeichert werden - auch bei uns oben - ist ziemlich raffiniert. Schaut euch dazu die Document-Frequency-Matrix einmal an. Fällt euch was auf?
text_matrixDocument-feature matrix of: 15 documents, 2,638 features (88.24% sparse) and 0 docvars.
features
docs frühere us-präsident donald trump vorwahl präsidentschaftskandidatur
text1 1 1 1 5 2 1
text2 0 1 1 10 2 0
text3 0 0 3 13 3 1
text4 1 0 2 10 0 0
text5 0 0 2 29 0 0
text6 0 1 1 7 0 0
features
docs republikaner bundesstaat south carolina
text1 4 4 6 6
text2 5 2 2 2
text3 4 2 0 1
text4 2 3 1 1
text5 2 1 0 1
text6 3 2 0 0
[ reached max_ndoc ... 9 more documents, reached max_nfeat ... 2,628 more features ]Tipp: Es ist geübte Praxis, alle Pakete, die im Verlauf eines Scriptes benötigt werden, ganz oben im Script aufzurufen. Das heisst, anstelle dass ihr nun die bisherigen Pakete (readxl, stringr, quanteda, etc.) jeweils an den Stellen installiert und aktiviert, an denen der relevante Code folgt, könnt ihr alle Pakete oben zu Anfang eures Scripts aufrufen. Sollte ein weiteres Paket im Verlauf nötig sein, könnt ihr es oben einfügen und ausführen. In der Zukunft habt ihr dann direkt zu Anfang einen Überblick über die benötigten Pakete und sie stören den Ablauf im weiteren Script nicht mehr.
17. Dezember 2025
Bevor man mit latenten Konzepten wie Emotionalität, Humor, etc. weiter arbeitet, ist es wichtig, sich zu vergewissern, dass die gemessenen Konzepte valide und reliabel sind. Hohe Reliabilität bedeutet, dass verschiedene Leute bei der Einschätzung von gegebenen Texten in Bezug auf ein Kozept (z.B. Humor) zu ähnlichen oder gleichen Ergebnissen kommen. Dies macht eine Analyse intersubjektiv nachvollziehbar und die Chance ist hoch, dass auch andere Coder in der Zukunft zu dem gleichen Ergebnis kommen. Reliabilität stellt daher ein wichtiges wissenschaftliches Gütekriterium dar.
Niedrige Reliabilität wiederum liegt vor, wenn sich verschiedene Leute bei gegebenen Texten nicht auf die Ausprägung eines Konzeptes einigen können. Wenn beispielsweise Coder A zu einem Text sagt, dass dieser humorvoll ist, Coder B hingegen sagt, dass der Text nicht humorvoll ist, dann können wir uns nicht sicher sein, welcher Fall nun zutrifft. Weder das eine, noch das andere scheint uneingeschränkt richtig zu sein. Es fehlt also eine reliable Einschätzung und es kann mit einer Analyse nicht fortgefahren werden.
Es gibt etliche Gründe, warum die Reliabilität möglicherweise unzureichend ist. Verschiedene Leute könnten (z.B. aus kulturellen, alters oder geschlechtlichen) Gründen Konzepte unterschiedlich wahrnehmen. Manche Konzepte sind schwierig klar abzutrennen oder schwierig zu verstehen. Auch Texte können schwierig sein was eine klare Einordnung betrifft. Teils existieren auch schlicht Missverständnisse und ein ausführlicheres Training der Coder kann Abhilfe schaffen.
Während Validität primär über die Literatur und Theorie begründet wird, wird bei Inhaltsanalysen die Reliabilität häufig auch als Indikator für die Validität herangezogen. Obwohl hohe Reliabilität eine notwendige, aber keine hinreichende Bedingung für Validität ist, gibt es bei sozialwissenschaftichen (oft latenten) Konzepten oft keine “endgültige Wahrheit”. Daher wird, bei hoher Reliabilität im Urteil, die Meinung von Codern oft als endgültige Wahrheit definiert.
Es existieren unterschiedliche Masszahlen um die Reliabilität zwischen Codern quantitativ zu bestimmen. Eine sehr populäre Masszahl ist Krippendorff’s Alpha, welche auch wir verwenden. Krippendorff’s Alpha ist sehr flexibel was die Anzahl der Coder betrifft und kommt mit unterschiedlich skalierten Bewertungen zurecht. Auf einer Skala von 0 bis 1 gibt diese Masszahl an, wie gut die Urteile verschiedener Coder zu gleichen Sachverhalten (bei uns Texten) übereinstimmen. Eine 1 zeigt eine perfekte Reliabilität an, eine 0 die vollständige Abwesenheit von Reliabilität.
Für ein Mindestmass an wissenschaftlicher Güte und Reliabilität sollte Alpha mindestens Werte von 0,667 annehmen, besser wären Werte von 0,8 und höher.
Sofern Bewertungen verschiedener Coder zu mehreren Texten vorhanden sind, lässt sich Krippendorff’s Alpha in R leicht ausrechnen.
# Ein neues Paket wird für die Berechnung von Krippendorff's Alpha benötigt
install.packages("irr") Warning: Paket 'irr' wird gerade benutzt und deshab nicht installiertlibrary(irr)# Die relevanten Spalten aus "data", also die Bewertungen der drei Coder
# werden in einer neuen Datentabelle abgespeichert. (Ihr seht dann rechts
# im Environment den neuen Datensatz mit dem namen "bewertungen")
bewertungen <- data[, c("tone_trump_c1","tone_trump_c2", "tone_trump_c3")]
# Berechnung von Krippendorff's Alpha
kripp.alpha(t(bewertungen), method = "ordinal") Krippendorff's alpha
Subjects = 15
Raters = 3
alpha = 0.777 Mit dem Befehl kripp.alpha() wird Krippendorff’s Alpha berechnet. t() innerhalb von kripp.alpha()ist notwendig, um die Datentabelle bewertungen zu transponieren und sie in ein Format zu bringen, welches den Spezifikationen des Befehls kripp.alpha() entspricht.
Achtet darauf, hier korrekt vorzugehen, andernfalls kann es zu falschen Ergebnissen führen oder dazu, dass es nicht funktioniert und ihr frustriert seid!
Im Output von kripp.alpha() sehen wir drei Angaben. “Subjects” gibt an, wie viele Texte codiert wurden. “Raters” gibt an, wie viele Coder involviert waren und alpha gibt uns schliesslich das gewünschte Krippendorff’s Alpha für die Reliabilität der drei Codierer zu diesen 15 Texten. In diesem fiktiven Beispiel ist alpha 0.777. Das ist eine ausreichende, wenngleich nicht optimale Reliabilität. Wenn ihr in die Daten schaut, könnt ihr sehen, dass die Codierer mit ihrem Urteil bei drei von 15 Texten nicht übereingestimmt haben.
Wichtig ist, dass ihr das korrekte Skalenniveau beachtet. Das wird über die Option method = "ordinal" oder method = "nominal" innerhalb des Befehls kripp.alpha() gelöst. Bei Tonalität (wie in unserem Fall) kann meist argumentiert werden, dass ein ordinales Skalenniveau vorliegt, da die Abstände zwar unklar sind, aber eine klare Reihung oder Ordnung existiert. Das wird bei der Berechnung der Reliabilität berücksichtigt. So ist es beispielsweise weniger gravierend, wenn ein tatsächlich positiver Artikel als neutral eingestuft wird, als wenn er als negativ eingestuft wird. Letztere fehlende Übereinstimmung ist somit „schwerwiegender“ als erstere, da die Distanz zwischen den Kategorien größer ist. Bei einer nominalen Skala wäre diese Distanz irrelevant, und beide Fehlklassifikationen würden gleich gewichtet.
Deutlicher wird es bei folgenden Beispielen: Wir wollen das Sentiment eines Textes auf einer feingliedrigen 7-er Skala bestimmen. Von “sehr negativ” über “negativ”, “etwas negativ”, “neutral”, bis hin zu “sehr positiv”. Wenn nun eine Person einen Text als “sehr negativ” und eine andere Person den selben Text als “negativ” einstuft, dann ist das zwar ein Widerspruch, aber inhaltlich liegen sie schon sehr nahe bei einander. Der Widerspruch wäre viel dramatischer, wenn eine dritte Person der Meinung ist, dass der selbe Text “positiv” sei. Letzteres würde gravierendere Abzüge hinsichtlich der Reliabilität geben, was intuitiv sinnvoll ist.
Wenn wir hingegen codieren, um was für einen Akteurstyp sich ein Akteur handelt, haben wir eine nominale Skala. Wenn eine Person einen Akteur als “NGO” klassifiziert, eine andere Person den selben Akteur hingegen als “Regierung”, dann ist der Widerspruch im Regelfall genauso gravierend wie wenn eine dritte Person den betreffenden Akteur als “Opposition” bezeichnet. Wir haben in jedem Fall einen gleichwertigen Widerspruch, es gibt kein “weniger falsch” oder “fast richtig”, wie das bei ordinalen (oder metrischen) Variablen der Fall sein kann.
Wichtig: Die Reliabilität wird für jedes Konzept/Kategorie extra bestimmt und angegeben. Sollte die Güte der Reliabilität nicht den gewohnten Gütekriterien entsprechen (im Regelfall mindestens 0.667, idealerweise mindestens 0.8), dann solltet ihr überlegen, was die Gründe hierfür sind und ggf. darauf reagieren.
17. Dezember 2025
Zusätzlich schauen wir uns heute an, wie statistische Tests in R durchgeführt werden können. Dabei wird nicht oder kaum darauf eingegangen, wie diese Tests mathematisch funktionieren oder in welchen Situationen und unter welchen Bedingungen sie geeignet sind. Schaut dafür bitte in die Aufzeichnungen oder Unterlagen eurer Methoden/Statistik-Kurse.
Generell gilt (grob gesagt) bei einem empirischen Projekt bzw. der statistischen Auswertung folgende Prozessreihenfolge:
1) Was ist mein Forschungsinteresse, meine Forschungsfrage und/oder meine Hypothese(n)
2) Welches Analyse (z.B. statistischer Test) beantwortet meine Forschungsfrage oder Hypothese(n)
3) Sind die Bedingungen für die Analyse/den Test gegeben.
4) Analyse/Test durchführen
Punkt 1 ist für euch meist bereits geklärt bzw. das wurde bereits behandelt. Zu Punkt 2 und 3 habt ihr etwas in euren Methoden/Statistikkursen gelernt, diese solltet ihr nötigenfalls nochmals konsultieren. Punkt 4 wird euch hier beigebracht. Als Forschungsfrage interessiert uns für dieses Tutorial, ob sich die Anzahl an Fotos in den Artikeln eines Outlets (z.B. Handelsblatt) von der Anzahl an Fotos in Artikeln anderer Outlets unterscheidet. In eurem Projekt wird die Frage anders, aber vermutlich ähnlich aussehen, beispielsweise, ob sich die Tonalität oder das Framing der Berichterstattung zwischen zwei Ländern unterscheidet.
In einem/eurem richtigen Projekt solltet ihr Punkte 2 und 3 durchführen. Für dieses Tutorial überspringen wir diese Punkte und legen uns auf den Mittelwertvergleich (t-Test) fest. Ob dieser Test für euch in Frage kommt, hängt von eurer Forschungsfrage ab und der Art der Daten, die ihr habt. Das solltet ihr selbst einschätzen können.
Um die Durchführung in R zu lernen, arbeiten wir erneut mit unserem Testdatensatz. Bitte lest diesen erneut in R ein. Wer sich nicht erinnert wie das geht, findet die Anleitung oben in den Ausführungen.
Der t-Test ist ein häufig angewandter statistischer Test um zu prüfen, ob sich ein Mittelwert einer Variable von einem anderen Wert (z.B. der Mittelwert einer anderen Variable oder von einem festen Wert) unterscheidet. Der t-Test ist beispielsweise gefragt, wenn man testen möchte, ob sich die mittlere Körpergröße einer Gruppe von Menschen von der Durchschnittskörpergröße einer anderen Gruppe unterscheidet. In unserem Kontext wäre ein Anwendungsgebiet, ob sich die mittlere Anzahl an Nennungen von “Trump” in Artikeln eines Zeitungshauses von der mittleren Anzahl an Nennungen von “Trump” in Artikeln eines anderen Zeitungshauses unterscheiden.
Für unsere Frage interessieren uns als Variable die Anzahl der Fotos. Und die Gruppen, zu denen wir die Anzahl an Fotos vergleichen wollen, sind vier unterschiedliche Outlets (hier: Spiegel Online, Zeit Online, Handelsblatt und Tagesschau). Zu Beginn ist es immer hilfreich, sich einen Überblick zu verschaffen. Dazu gehört zunächst, sich die Mittelwerte der Anzahl der Fotos pro Artikel anzuschauen.
Die durchschnittliche Anzahl an Fotos insgesamt lässt sich leicht ausrechnen, das haben wir bereits oben gelernt:
mean(data$pics)[1] 1.533333Jetzt wollen wir uns anschauen, was die Durchschnittswerte für die vier Outlets sind. Es gibt unterschiedliche Wege, den Mittelwert für mehrere Gruppen zu berechnen. Eine der elegantesten Lösungen ist (dafür braucht ihr das Package dplyr):
outlet_means <- data %>% group_by(outlet) %>% summarise(mean_value = mean(pics))
outlet_means# A tibble: 4 × 2
outlet mean_value
<chr> <dbl>
1 handel 3
2 spon 1.8
3 tages 1
4 zon 0.5Wir sehen, dass es erhebliche Unterschiede in der Anzahl der Fotos pro Artikel zwischen den vier Outlets gibt. Jetzt wollen wir aber wissen, ob der Unterschied in der Anzahl der Fotos zwischen Handelsblatt und dem Rest auch statistisch signifikant ist.
Dazu wenden wir nun schon den t-Test an. Dieser wird mit dem Befehl t.test() in R aufgerufen. Damit R weiss, welche Mittelwerte es vergleichen soll, müssen wir diese R mitteilen. Die Logik ist dabei t.test(Werte der Variable von Gruppe A, Werte der Variable von Gruppe B). Die Variable ist die Anzahl der Fotos und die Gruppen sind unsere Outlets.
Dazu teilen wir unsere Daten in die beiden Gruppen, die uns interessieren. Einmal alle Artikel vom Handelsblatt und das andere Mal der Rest. Das geht mit dem subset()-Befehl:
handel_data <- subset(data, data$outlet=="handel")
# Mit diesem Befehl werden alle Daten, die in der Spalte "outlet" den Wert "handel" haben in eine neue Tabelle namens "handel_data" geschrieben
no_handel_data <- subset(data, data$outlet!="handel")
# Das "!=" bedeutet "nicht". Hier werden also alle Daten, die in der Spalte "outlet" NICHT den Wert "handel" haben in eine neue Tabelle namens "no_handel_data" geschrieben. Nun können wir schon den t-Test auf die Daten beider Gruppen anwenden:
t.test(handel_data$pics, no_handel_data$pics)
Welch Two Sample t-test
data: handel_data$pics and no_handel_data$pics
t = 0.9067, df = 2.0892, p-value = 0.4567
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-6.520178 10.186844
sample estimates:
mean of x mean of y
3.000000 1.166667 Alternativ kann man sich die Befehle subset() sparen, und die Definition der Gruppen (=> Teilmengen), also Artikel von Handelsblatt vs. Artikeln von allen anderen direkt im t-test-Befehl machen. Das geht so:
t.test(data$pics[data$outlet!="handel"], data$pics[data$outlet=="handel"])
Welch Two Sample t-test
data: data$pics[data$outlet != "handel"] and data$pics[data$outlet == "handel"]
t = -0.9067, df = 2.0892, p-value = 0.4567
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-10.186844 6.520178
sample estimates:
mean of x mean of y
1.166667 3.000000 Hinweis: In aller Regel dauert es in einem realen Projekt deutlich länger, die Daten in die Form zu bekommen, die es erlaubt den angestrebten Test durchzuführen, als die Dauer (oder Kompliziertheit) des Tests selbst. Oft muss man Daten erst bereinigen oder umformen, was teils sehr aufwendig ist. Der finale Test geht dann oft sehr schnell und einfach. Also: Nicht verunsichern lassen, wenn ihr viel Zeit darauf verwendet, die Daten in eine Form zu bekommen, die notwendig ist den t-Test (oder andere Tests) anzuwenden.
Zurück zum Beispiel. Im Ergebnis des t.test()-Befehls bekommt man nun ein mehrzeiliges Ergebnis. Das wird wie folgt interpretiert:
In der ersten Teile seht ihr nochmals den Code, der genutzt wird, die Daten für den t-Test zu definieren, also die beiden Gruppen.
In den letzten zwei Zeilen seht ihr den Mittelwert für die beiden Gruppen. x ist die linke Gruppe, also alle Outlets ohne Handelsblatt. Demnach haben die drei Outlets (Spiegel Online, Zeit Online und Tagesschau) einen Mittelwert von 1,1667 Bilder pro Artikel. Das Handelsblatt hingegen 3 (diesen Wert haben wir oben schon herausgefunden, es ist immer gut, Ergebnisse auf Plausibilität zu prüfen und sie idealerweise gegen zu checken).
Der p-Wert in Zeile 2 ganz rechts gibt euch schliesslich an, ob sich die Mittelwerte der beiden Gruppen statistisch unterscheiden. Es handelt sich um einen statistisch signifikanten Unterschied, wenn p < 0,05. Mit einem p-Wert von 0,457 handelt es sich bei der Anzahl an Bildern also nicht um einen statistisch signifikanten Unterschied zwischen den beiden Gruppen.
Das Ergebnis mag verblüffen, da im Handelsbaltt im Mittel mehr als doppelt so viele Fotos sind als in allen anderen Outlets. Allerdings haben wir in dem Testdatensatz auch nur sehr wenige Daten. Damit ist es schwer eine robuste Aussage über die statistische Signifikanz des Unterschieds zu treffen. Bei kleinen Stichproben kann die Varianz stark schwanken, was die Zuverlässigkeit eines t-Tests beeinträchtigt. In solchen Fällen ist es sinnvoll, mit mehr Daten die Stichprobengrösse zu erhöhen, um eine genauere Einschätzung der Mittelwertunterschiede der beiden Gruppen zu erhalten. In unserem Fall konkret sind die Unterschiede in der durchschnittlichen Anzahl an Fotos zwischen den beiden Gruppen recht gross (der eine Wert ist mehr als doppelt so gross wie der andere). Es ist daher sehr wahrscheinlich, dass die Unterschiede bei grösserer Stichprobengrösse signifikant werden (d.h., dass der p-Wert dann kleiner als 0,05 ist). Das ist aber keinesfalls garantiert. Es kann durchaus sein, dass wir zufällig ein paar Artikel aus dem Handelsblatt ausgefwählt haben, die viele Fotos beinhalten. Möglicherweise haben viele andere keine oder nur sehr wenige Fotos. Daher sollte man mit Prognosen vorsichtig sein und sich nur auf tatsächliche Tests mit tatsächlichen Daten verlassen.
Anstatt zu testen, ob ein Unterschied zwischen Variablen besteht, gibt es eine Reihe weiterer Testverfahren den Zusammenhang von Variablen zu prüfen. Eine solche Methode ist, die Korrelation zwischen zwei oder mehr Variablen zu testen. Es gibt drei Korrelationstypen: a) Positive Korrelation: Wenn die eine Variable steigt, steigt auch die andere, b) negative Korrelation: Wenn die eine Variable steigt, sinkt die andere, c) Keine Korrelation: Es gibt keinen erkennbaren Zusammenhang zwischen den Variablen. Man könnte beispielsweise untersuchen, ob zwischen der Körpergröße von Menschen und deren Gewicht ein Zusammenhang besteht. Da wir wissen, dass bei steigender Körpergröße das Gewicht in der Tendenz steigt, spricht man hier von einer positiven Korrelation.
Wie den t-Test, kann man die Korrelation in R leicht und mit nur einem Befehl testen. Der Befehl hierfür ist cor.test() und die Syntax ist identisch zu der des t.test(). Aber auch hier ist es nochmal wichtig zu sagen, dass ihr den Korrelationstest nur anwenden solltet, wenn es eure Hypothese oder Forschungsfrage erforderlich macht. Das heißt, ihr startet bei der Forschungsfrage und schaut, welcher Test notwendig ist. Diese Arbeit kann in einem Tutorial nicht geleistet werden, da eure Forschungsfragen individuell sehr unterschiedlich sind, was auch eure Anforderungen an die Methodik unterschiedlich macht.
Zur Illustration wählen wir hier hingegen eine hypothetische Forschungsfrage bzw. eine Hypothese, die sich mit unseren Beispieldaten prüfen lässt: Hängt die Länge der Überschrift, mit der Länge des Artikels zusammen? Unsere Hypothese wäre, dass hier kein Zusammenhang besteht, da Überschriften gewöhnlich sehr ähnlich und daher von ähnlicher Länge sind, ganz unabhängig, wie lang der Artikel ist.
Um diese Hypothese zu prüfen benötigen wir zwei Variablen: Die Längen der Überschriften und die Längen der Artikeltexte. Wir haben zwar die Überschriften und Texte, aber nicht die Länge dieser beiden Variablen. Das heißt, wir müssen diese Information erst aus den Überschriften und Texten generieren. Das ist ein gutes und praxisnahes Beispiel, welches zeigt, dass der Weg, Daten in das benötigte Format zu bekommen, beträchtlich länger und aufwendiger sein kann als der finale Test.
Um die Länge der beiden Variablen headline und text zu bestimmen, benötigen wir den Befehl nchar(). Wie der Name insinuiert, bestimmt nchar() die Länge von Texten (Variablen vom Type character):
data$length_head <- nchar(data$headline)
data$length_text <- nchar(data$text)Nachdem wir in zwei (zugegeben einfachen) Schritten die Textlänge der beiden Variablen bestimmt haben, können wir direkt den Korrelationstest mit nur einer Zeile Code darauf anwenden. Die Syntax ist quasi identisch zu der des t-Tests.
cor.test(data$length_head, data$length_text)
Pearson's product-moment correlation
data: data$length_head and data$length_text
t = -1.5046, df = 13, p-value = 0.1563
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.7495077 0.1584097
sample estimates:
cor
-0.3851033 Auch die Interpretation ist ähnlich zum t-Test. In der untersten Zeile wird der Korrelationskoeffizient angezeigt. Dieser ist mit -0,39 negativ. Das heisst, wenn die Überschriften länger werden, werden die Artikeltexte in der Tendenz kürzer. Allerdings ist der p-Wert (Zeile 2) mit 0,16 größer als 0,05. Das heisst, dass kein signifikanter Zusammenhang zwischen den Längen der beiden Variablen besteht. Unsere Hypothese, dass es keinen Zusammenhang zwischen der Länge der Überschrift und der Länge des Artikeltextes gibt kann daher vorläufig bestätigt werden. Auch hier haben wir allerdings noch sehr wenig Daten. Idealerweise wären für einen aussagekräftigeren Test mehr Daten gefordert.
Bitte informiert euch für die Auswertung eurer Daten, welcher Test bzw. welche Analyse für eure Forschungsfrage sinnvoll bzw. gefordert ist. Hier wurden mit dem t-Test und dem Korrelationstest zwei Verfahren gezeigt. Diese können für eure Fragen relevant sein, das muss aber nicht so sein. Nicht ideal wäre, wenn ihr einen Test anwendet, der für eure Forschungsfrage keine Relevanz hat, bzw. unsinnig ist. Konsultiert im Zweifel eure Aufzeichnungen der Methoden und Statistik-Veranstaltungen, fragt eure Kommilitoninnen oder mich.
07. Januar 2026
In den nächsten drei Sitzungen werden vier verschiedene Verfahren für die automatisierte Inhaltsanalyse vorgestellt. Begonnen wird in dieser Sitzung mit der lexikonbasierten Analyse.
Das Grundprinzip der lexikonbasierten Analyse ist einfach: Wir nehmen an, das wir basierend auf den Wörtern in einem Text auf eine abstraktere Bedeutungsebene rückschliessen können. Die Bedeutungsebene ist unser Konstrukt, z.B. Emotionalität oder Sentiment. Nun müssen wir, theoretisch fundiert, eine Liste erstellen oder eine existierende Liste nutzen, die regelt, welche Wörter für welches Konstrukt stehen. Beispielsweise würden Wörter wie “hassen” oder “Wut” vermutlich Indiz für ein negatives Sentiment des Textes sein. Hat man eine Wortliste (auch Lexikon oder Diktionär) erstellt, wendet man es auf seine Texte an. Dabei wird letztlich schlicht gezählt, wie oft die definierten Wörter vorkommen. Final legt man fest, welche Regel nun genau gilt, um einen Text einem Konstrukt zuzurodnen. Reicht es bspw., wenn ein Wort aus der Liste in einem Text einmal vorkommt oder sagen wir, dass wir mindestens fünf Treffer pro Text haben wollen, bevor wir festlegen, dass ein bestimmtes Konstrukt in dem Text repräsentiert ist. Das muss theoretisch und konzeptionell begründet werden. Damit ist die formale Analyse beendet und wir müssen am Ende noch prüfen, ob die Messung valide ist, also dem entspricht, was wir tatsächlich, theoretisch messen wollen.
Lexikonbasierte Anwendungen haben einige Vorteile. So sind sie beispielsweise sehr transparent und weil sie rein deterministisch erfolgen sind sie auch immer perfekt reliabel. Allerdings ist die Validität oft gering, weil Wörter doppeldeutig sein können, Negationen existieren, Ironie nicht erkannt werden kann, etc. Schaut hierfür bitte nochmal in die Folien der entsprechenden Sitzung, darin wird diese sehr wichtige Thematik ausführlicher besprochen.
Wir arbeiten in diesem Tutorial erneut mit dem Beispieldatenssatz, den ihr schon kennt. Zusätzlich laden wir einen weiteren Datensatz herunter. Nutzt aber gerne direkt auch eure eigenen Texte. Stärker als in der Vergangenheit können hier allerdings Probleme auftreten. Beispielsweise ist der Beispieldatensatz deutschsprachig; das ist nicht bei all euren Texten der Fall und erfordert teils Anpassungen.
Oben haben wir schon gesehen, dass in dem Paket quanteda bereits Listen von sog. “Stopwords” inkludiert sind. Also Wörter, die in aller Regel keine inhaltliche Bedeutung für einen Text haben. Genauso sind in quanteda auch bereits ein paar inhaltliche Listen integriert; namentlich das Lexicoder Sentiment Dictionary (LSD). Schauen wir uns das mal an.
library(quanteda)
data_dictionary_LSD2015Dictionary object with 4 key entries.
- [negative]:
- a lie, abandon*, abas*, abattoir*, abdicat*, aberra*, abhor*, abject*, abnormal*, abolish*, abominab*, abominat*, abrasiv*, absent*, abstrus*, absurd*, abus*, accident*, accost*, accursed* [ ... and 2,838 more ]
- [positive]:
- ability*, abound*, absolv*, absorbent*, absorption*, abundanc*, abundant*, acced*, accentuat*, accept*, accessib*, acclaim*, acclamation*, accolad*, accommodat*, accomplish*, accord, accordan*, accorded*, accords [ ... and 1,689 more ]
- [neg_positive]:
- best not, better not, no damag*, no no, not ability*, not able, not abound*, not absolv*, not absorbent*, not absorption*, not abundanc*, not abundant*, not acced*, not accentuat*, not accept*, not accessib*, not acclaim*, not acclamation*, not accolad*, not accommodat* [ ... and 1,701 more ]
- [neg_negative]:
- not a lie, not abandon*, not abas*, not abattoir*, not abdicat*, not aberra*, not abhor*, not abject*, not abnormal*, not abolish*, not abominab*, not abominat*, not abrasiv*, not absent*, not abstrus*, not absurd*, not abus*, not accident*, not accost*, not accursed* [ ... and 2,840 more ]Wir sehen, dass LSD tatsächlich sogar vier Listen enthält, mit jeweil mehreren tausend englischen Wörtern, die entweder negativ oder positiv sind, oder der jeweiligen Negation entsprechen. Es fällt auf, dass einige Wörter ein * am Ende enthalten. Dies zeigt an, dass nur der Wortstamm in der Liste enthalten ist, aber alle weiteren Zeichen nach dem Stamm, dann auch diesem Wort entsprechen. Das ist wichtig, da sehr viele Wörter eine Flexion, also eine grammatikalische Veränderung der Grundform erhalten, uns diese Flexion aber in vielen Fällen nicht interessiert. Diese Nuancen sind in der Grammatik relevant und um die Nuancen von Sprache zu verstehen, für eine Inhaltsanalyse aber oft nicht bedeutend.
Zum Beispiel würde „abolish*“ sowohl „abolish“, „abolishing“ als auch „abolishment“ erfassen. Dies ist sehr praktisch, da man dafür nicht jede Wortform einzeln in ein Lexikon aufnehmen muss. Technisch handelt es sich dabei um eine stamm-basierte Wildcard, bei der alle Wörter berücksichtigt werden, die mit demselben Wortanfang beginnen.
Eine weitere Möglichkeit, unterschiedliche Wortformen zusammenzufassen, ist das Stemming. Beim Stemming werden Wörter mithilfe einfacher Regeln auf einen Wortstamm reduziert, indem typische Endungen entfernt werden. Dieser Wortstamm ist häufig keine linguistisch korrekte Wortform, erfüllt aber den Zweck, verschiedene Flexions- und Ableitungsformen automatisch zusammenzuführen.
bedrohlich, Bedrohung, bedrohte, bedrohen → bedroh
Für Inhaltsanalysen ist diese Reduktion oft sinnvoll, da unterschiedliche Flexionsformen oder Wortarten häufig dasselbe inhaltliche Signal tragen (z. B. negatives Sentiment). Ob ein Ereignis in der Vergangenheit oder Gegenwart beschrieben wird, ist dann weniger relevant als die Bewertung selbst.
Der Vorteil des Stemmings liegt in seiner Einfachheit und Geschwindigkeit. Nachteilig ist jedoch, dass unterschiedliche Wortarten und Bedeutungsnuancen zusammenfallen können und der resultierende Stamm nicht immer eindeutig interpretierbar ist. Das maximiert teils Treffer, aber nicht unbedingt Präzision. Beispielsweise würden die Wörter “demokratisch”, “Demokratie” und “demokratisieren” alle auf den Stamm “demokrat” gekürzt werden. Für viele Fragestellungen sind das inhaltlich verschiedene Konzepte, diese Nuancen gehen verloren. Gleichzeitig kann man zu viel erfassen, wenn man zu kurze Stämme wählt, z.B. bei den Wörtern “rechts” und “Recht” oder “rechtlich”.
Eine weitergehende Methode ist die Lemmatisierung. Hierbei werden Wörter auf ihre sprachlich korrekte Grundform (Lemma) zurückgeführt. Im Gegensatz zum Stemming berücksichtigt die Lemmatisierung grammatische Informationen wie Wortart, Zeitform oder Numerus. Die verschiedenen Formen: lief, laufe, laufen, laufte, usw. würden alle auf “laufen” reduziert.
Der Vorteil der Lemmatisierung besteht darin, dass die Ergebnisse linguistisch korrekt und besser interpretierbar sind. Sie eignet sich besonders für lexikonbasierte Inhaltsanalysen, bei denen Wörter gezielt Kategorien zugeordnet werden sollen. Gleichzeitig ist Lemmatisierung methodisch aufwendiger, da sie komplexe Sprachmodelle und umfangreiches grammatikalisches Wissen erfordert.
Wichtig ist, dass sowohl das verwendete Lexikon als auch die zu analysierenden Texte derselben Vorverarbeitungslogik folgen. Lexikonbasierte Analysen setzen voraus, dass Wörter in Lexikon und Text in einer kompatiblen Form vorliegen. Ist ein Lexikon lemmatisiert, müssen auch die Texte lemmatisiert werden; basiert das Lexikon auf Wortstämmen oder Wildcards, müssen die Texte entsprechend unverändert oder kompatibel vorverarbeitet sein.
Logischerweise gilt das auch für die Sprache. LSD enthält hier nur englische Wörter. Das hilft uns also gar nichts, wenn wir nur deutsche Texte haben, wie in unseren Testdaten. Wir verwenden hierfür also ein anderes, ein deutschsprachiges Lexikon, SentiWS.
Dafür laden wir zunächst hier https://wortschatz.uni-leipzig.de/de/download/ SentiWS in der Version v 2.0 herunter. Wir erhalten ein zip-file mit drei .txt Dateien. Zwei davon lesen wir nun ein. Dafür müssen wir uns zunächst einmal anschauen, wie die Daten in der .txt-Datei vorliegen, damit wir unseren Einlese-Befehl richtig strukturieren (bzw. dass die Daten so eingelesen werden, wie wir es dann letztlich haben wollen).
neg <- read.table("C:/Users/Name/Documents/Studium/WS25/HypeHorror/data/SentiWS_v2.0:Negative.txt",
sep = "\t",
header = FALSE,
encoding = "UTF-8",
)Wie immer schauen wir uns das Ergebnis zunächst einmal an, auch um zu prüfen ob alles geklappt hat.
neg[1:20,] V1 V2 V3
1 Abbau|NN -0.0580 Abbaus,Abbaues,Abbauen,Abbaue,Abbauten
2 Abbruch|NN -0.0048 Abbruches,Abbrüche,Abbruchs,Abbrüchen,Abbruche
3 Abdankung|NN -0.0048 Abdankungen
4 Abdämpfung|NN -0.0048 Abdämpfungen
5 Abfall|NN -0.0048 Abfalles,Abfälle,Abfalls,Abfällen,Abfalle
6 Abfuhr|NN -0.3367 Abfuhren
7 Abgrund|NN -0.3465 Abgründe,Abgrunde,Abgrundes,Abgrunds,Abgründen
8 Abhängigkeit|NN -0.3653 Abhängigkeiten
9 Ablehnung|NN -0.5118 Ablehnungen
10 Ablenkung|NN -0.0435 Ablenkungen
11 Abnahme|NN -0.0048 Abnahmen
12 Abneigung|NN -0.0048 Abneigungen
13 Abnutzung|NN -0.0048 Abnutzungen
14 Abriss|NN -0.0048 Abrisse,Abrissen,Abrisses
15 Abrutsch|NN -0.0048 Abrutschen,Abrutsche,Abrutsches,Abrutschs
16 Abschaffung|NN -0.0580 Abschaffungen
17 Abschreckung|NN -0.0048 Abschreckungen
18 Abschreibung|NN -0.3345 Abschreibungen
19 Abschuß|NN -0.0048 Abschüsse,Abschusses,Abschüssen
20 Abschuss|NN -0.0048 Abschüsse,Abschusse,Abschusses,AbschüssenDie Form ist hier noch etwas ungünstig. Um mit den Daten arbeiten zu können, müssen wir sie ein wenig umformen.
Wichtig: Solche Umformungen sind häufig notwendig und teils aufwendig. Sie gehören nicht strikt zur Inhaltsanalyse sind aber Bestandteil quasi jeder Arbeit mit Daten. Wenn ihr ein anderes existierendes Dictionary/Lexikon verwendet, sind sehr wahrscheinlich andere Anpassungen notwendig! Je nach dem ist hier ein wenig Arbeit notwendig.
Wir müssen nun zunächst alle relevanten Inhalte von den irrelevanten isolieren. Was uns interessiert: die jeweiligen Wörter. Das heisst die Grundform in Spalte 1 (davon haben wir hier 1827 Wörter) und die jeweiligen Flexionen in Spalte 3.
neg_words <- unique(c(
sub("\\|.*", "", neg[[1]]),
unlist(strsplit(neg[[3]], ","))
))Jetzt haben wir eine lange Liste mit 17932 Wörtern die als negativ markiert sind. Diese Liste können wir nun auf unseren Textkorpus anwenden und analysieren, wie negativ unsere Texte sind.
Hinweis: Hier arbeiten wir mit keiner Form der Reduzierung der Wörter, sondern haben jeweils für die Grundformen von Wörtern allerlei Flexionen explizit auch mit aufgelistet, deswegen wurde die Liste bei “nur” 1827 Grundformen nun auch so lang.
Nochmal zur Wiederholung lesen wir zunächst unsere Daten korrekt ein (identisch zu oben).
text_tokens <- tokens(data$text,
remove_punct = TRUE)
text_matrix <- dfm(text_tokens)
text_matrixDocument-feature matrix of: 15 documents, 2,816 features (85.97% sparse) and 0 docvars.
features
docs der frühere us-präsident donald trump hat die vorwahl zur
text1 11 1 1 1 5 4 12 2 1
text2 18 0 1 1 10 4 11 2 1
text3 32 0 0 3 13 5 26 3 2
text4 12 1 0 2 10 3 14 0 1
text5 27 0 0 2 29 8 30 0 1
text6 15 0 1 1 7 1 11 0 1
features
docs präsidentschaftskandidatur
text1 1
text2 0
text3 1
text4 0
text5 0
text6 0
[ reached max_ndoc ... 9 more documents, reached max_nfeat ... 2,806 more features ]Tipp: Es ist üblich, bei der Arbeit mit Textdaten, alle Wörter in Kleinschreibung zu behandeln. Das haben wir hier nun nicht gemacht, ist aber generell ratsam und lässt sich auch mit einer einzelnen Zeile oben im Code bewerkstelligen. Einfach mal selbst versuchen.
Jetzt führen wir die eigentliche Inhaltsanalyse basierend auf unserem Lexikon durch und lassen uns das Ergebnis anzeigen.
##### 2.2 Features aus Diktionär identifizieren #####
ergebnis <- text_matrix %>%
dfm_lookup(dictionary = dictionary(list(negative = neg_words)))
ergebnisDocument-feature matrix of: 15 documents, 1 feature (0.00% sparse) and 0 docvars.
features
docs negative
text1 8
text2 8
text3 12
text4 10
text5 30
text6 13
[ reached max_ndoc ... 9 more documents ]So schnell kann es gehen. Wieder nur zwei Zeilen Code und wir sehen wie viele der Wörter aus unserer “negativ”-Liste in den jeweiligen Texten gefunden wurden. Das ist schon mal ein erster Erfolg. In einem realen Projekt sollte man sich die Ergebnisse nun noch im Detail anschauen und die Validität prüfen. Ist es glaubhaft, dass der eine Text nur so wenige, der andere aber so viele Treffer hat? Auch der Vergleich mit eurer menschlichen Codierung ist hier relevant. Korrelieren menschliche Codierung und das hier vorliegende Ergebnis?
Wenn wir mit dem Ergebnis nun weiterarbeiten, fällt auf, dass die Texte unterschiedlich lang sind und es ist erwartbar, dass längere Texte im Durchschnitt auch mehr negative Wörter enthalten werden. Wir sollten daher auf die Artikellänge normieren. Um also mit den Ergebnissen arbeiten, fügen wir die gewonnenen Erkentnisse unserer Haupttabelle hinzu.
data$negativität <- as.numeric(ergebnis[, "negative"])Jetzt können wir die Negativität in Abhängigkeit der Textlänge berechnen:
data$relative_neg <- data$negativität/data$word_countDas ist schon mal besser. Um tatsächliche Erkenntnis zu erzeugen, wenden wir ein Verfahren der deskriptiven Statistik an, das wir schon von oben kennen:
data %>% group_by(outlet) %>% summarise(mean_value = mean(relative_neg))# A tibble: 4 × 2
outlet mean_value
<chr> <dbl>
1 handel 0.0222
2 spon 0.0201
3 tages 0.0406
4 zon 0.0286Wir sehen, dass die relative Negativität in den Texten vom Handelsblatt, Spiegel Online und der Zeit recht ähnlich ist. Lediglich die Texte der Tagesschau bilden eine gewisse Ausnahme und sind im Mittel ein gutes Stück negativer. Hier würde man nun noch einen statistischen Test durchführen, um zu prüfen ob diese Intuition auch statistisch haltbar ist. Da unser Testdatensatz allerdings sehr klein ist, macht das in dem Fall keinen Sinn. Je nach Fragestellung/Hypothese wäre man dann schon fertig mit der Analyse.
Wichtige Einschränkung
Dieser Ansatz hatte eine wichtige Einschränkung, fällt es dir auf? Ein Hinweis kann der Blick in die Rohdaten liefern (also in die .txt-Version des heruntergeladenen Lexikons).
Und zwar haben wir jetzt alle Wörter gleich behandelt. Ein Wort wie “Stornierung” oder “Melodrama”, das vielleicht nur eine sehr leichte negative Tendenz hat wurde gleich behandelt wie ein Wort wie “Streit” oder “Hölle”, Wörter mit stark negativer Tendenz. Je nach dem kann das ein Problem sein oder nicht, das muss dann je nach Fall entschieden werden.
In diesen Daten wären noch genauere Informationen enthalten, nämlich eine Zuordnung zu jedem Wort auf einer Skala von -1 bis 1, wobei -1 für Negativ und 1 für Positiv steht. Auf die Art und Weise wie wir das Lexikon erzeugt haben, haben wir diese Zusatzinformationen verloren und alle Wörter gleich behandelt. Man könnte diese Informationen auch einbeziehen und würde damit möglicherweise ein nuancierteres Bild erhalten, wenn sehr negative Wörter dann ein höheres Gewicht bekommen.
Zudem ist die Liste sehr umfangreich und möglicherweise je nach Anwendungsgebiet zu unspezifisch; insbesondere wenn viele nicht sehr starke Wörter mitgezählt werden.
Verwendung des englischen Dictionary/Lexikons
Nur zum Spass können wir am Ende noch einmal das englischsprachige LSD-Lexikon auf unsere Texte anwenden. Da dies schon in quanteda existiert, funktioniert das denkbar einfach und eine Umformung und Vorarbeit ist nicht erforderlich.
result <- text_matrix %>%
dfm_weight(scheme = "prop") %>%
dfm_lookup(dictionary = data_dictionary_LSD2015[1:2])
resultDocument-feature matrix of: 15 documents, 2 features (0.00% sparse) and 0 docvars.
features
docs negative positive
text1 0.03926702 0.020942408
text2 0.03125000 0.010416667
text3 0.02825429 0.022199798
text4 0.05142857 0.014285714
text5 0.03466466 0.011303693
text6 0.02725367 0.004192872
[ reached max_ndoc ... 9 more documents ]Wir bekommen sowohl für das positive, als auch für das negative Lexikon jeweils Treffer. Wie kann das sein? Nun, erneut enthalten die Listen viele Wörter und teils überschneiden sich deutsche und englische Wörter schlicht. Die englische Form “abstrus” existiert beispielsweise auch im deutschen. Manchmal ist die Bedeutung ähnlich oder gleich, wie z.B. bei “abstrus”, teils aber auch sehr unterschiedlich (Stichwort False Friends), wie z.B. bei “fatal” oder “liberal”. Die Ergebnisse dieser Analyse sind also nicht glaubhaft und haben eine äusserst geringe Validität. Nur weil wir ein Ergebnis haben, ist es nicht automatisch richtig oder das Verfahren korrekt durchgeführt.
Nun wollen wir statt einem bereits existierenden Lexikon ein eigenes erstellen. Die Grundlogik, was R betrifft, ist sehr ähnlich. Der Hauptunterschied ist, logischerweise, dass wir anstatt ein bestehendes zu nutzen, nun ein eigenes erstellen. Das ist theoretisch anspruchsvoll und bedarf grosser Sorgfalt. Ihr solltet genau überlegen ob die Wörter relevant und gut gewählt sind und ob ihr alle Nuancen bedacht habt. Idealerweise prüft ihr das auch nochmals (Validierung im Team, mit Freunden, etc.). Was die Erstellung in R angeht, ist es denkbar einfach:
lexikon <- dictionary(list(negativ = c(
"schlecht", "schlechter", "schlechte", "schlechtes", "schlechten",
"problematisch", "problematische", "problematischen",
"bedenklich", "bedenkliche", "bedenklichen",
"fragwürdig", "fragwürdige", "fragwürdigen",
"inakzeptabel", "unakzeptabel",
"untragbar",
"verwerflich", "verwerfliche",
"skandal", "skandale", "skandalös", "skandalöse", "skandalösen",
"affäre", "affären",
"korrupt", "korruption", "korrupten", "korrumpiert",
"illegal", "illegale", "illegalen",
"rechtswidrig", "rechtswidrige", "rechtswidrigen",
"verfassungswidrig", "verfassungswidrige",
"undemokratisch",
"autoritäre", "autoritarismus", "autoritären",
"konflikt", "konflikte", "konflikthaft",
"krise", "krisen", "krisenhaft",
"eskalation", "eskalieren", "eskaliert",
"spaltung", "spalten", "gespalten",
"polarisierung", "polarisieren", "polarisiert",
"scheitern", "scheiterte", "gescheitert",
"versagen", "versagte", "versagt",
"fehlentscheidung", "fehlentscheidungen",
"fehlschlag", "fehlschläge",
"blockade", "blockieren", "blockiert",
"stillstand",
"ineffizient", "ineffizienz",
"bedrohung", "bedrohlich", "bedrohen", "bedrohte",
"gefahr", "gefährlich", "risiko", "risiken",
"unsicherheit", "unsicher",
"gewalt", "gewalttätig",
"terror", "terroristisch", "terrorismus",
"extremismus", "extremistisch",
"radikalisierung", "radikalisiert",
"misstrauen", "misstrauisch",
"vertrauensverlust", "glaubwürdigkeitsverlust",
"zweifel", "anzweifeln",
"kritik", "kritisch",
"vorwurf", "vorwürfe",
"delegitimierung", "delegitimieren",
"systemversagen",
"machtmissbrauch",
"intransparenz",
"lobbyismus",
"klientelpolitik",
"arbeitslosigkeit",
"rezession",
"inflation",
"armut",
"ungleichheit"), positive = c("Diese", "Liste", "ist", "nur", "zur", "Demonstration", "und", "hat","keine","inhaltliche","Funktion")
))Ihr listet letztlich einfach alle Wörter auf und fügt sie mit dem Befehl dictionary(list()) als Lexikon/Dictionary hinzu. Innerhalb des Befehls list() könnt ihr zudem gleichzeitig mehrere Listen von Wörtern erstellen. Hier seht ihr, dass ich nur eine Liste namens “negativ” erstellt habe und am Ende auch noch eine Liste names “positiv”. Man könnte anschliessend auf die gleiche Weise noch weitere Listen erstellen; achtet nur darauf, die Klammern korrekt zu setzen. Das c() steht dabei übrignes für combine und ist notwendig, damit einzelne Elemente in einen Vektor zusammen gefasst werden; in dem Fall unsere lange Liste an Wörtern.
Schauen wir uns das Ergebnis an.
lexikonDictionary object with 2 key entries.
- [negativ]:
- schlecht, schlechter, schlechte, schlechtes, schlechten, problematisch, problematische, problematischen, bedenklich, bedenkliche, bedenklichen, fragwürdig, fragwürdige, fragwürdigen, inakzeptabel, unakzeptabel, untragbar, verwerflich, verwerfliche, skandal [ ... and 94 more ]
- [positive]:
- diese, liste, ist, nur, zur, demonstration, und, hat, keine, inhaltliche, funktionAnschliessend können wir unser Lexikon direkt auf unsere Texte anwenden - genau wie zuvor (auch hier berechnen wir direkt die relative Anzahl)
result <- text_matrix %>%
dfm_weight(scheme = "prop") %>%
dfm_lookup(dictionary = lexikon)
resultDocument-feature matrix of: 15 documents, 2 features (13.33% sparse) and 0 docvars.
features
docs negativ positive
text1 0 0.04973822
text2 0 0.03541667
text3 0.001009082 0.03632694
text4 0.002857143 0.02571429
text5 0.001507159 0.05275057
text6 0.008385744 0.04192872
[ reached max_ndoc ... 9 more documents ]Was fällt uns auf?
Auch hier fügen wir das Ergebnis wieder zu unseren Hauptdaten hinzu und berechnen direkt die Korrelation mit dem Ergebnis der Analyse basierend auf dem existierenden Lexikons von oben.
data$eigene_negativität <- as.numeric(result[, "negativ"])
cor.test(data$relative_neg, data$eigene_negativität)
Pearson's product-moment correlation
data: data$relative_neg and data$eigene_negativität
t = 1.8288, df = 13, p-value = 0.09046
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.0779841 0.7831413
sample estimates:
cor
0.4523494 Wir haben eine positive Korrelation, die ist allerdings moderat bzw. mittelmässig. Was sagt uns das nun, welche Analyse war die richtige(re)? Auf welche Analyse würden wir uns nun verlassen?
Wir müssen uns sicher sein können, dass wir eine valide Analyse durchführen, denn auf unserer Analyse fusst die ganze Interpretation der Ergebnisse. Je nach Analyse kann diese ganz unterschiedlich ausfallen:
data %>% group_by(outlet) %>% summarise(mean_value = mean(eigene_negativität))# A tibble: 4 × 2
outlet mean_value
<chr> <dbl>
1 handel 0.00184
2 spon 0.00107
3 tages 0.00322
4 zon 0.00333Mit dem eigenen Lexikon ist die Tagesschau nicht mehr Spitzenreiter bei der Negativität ihrer Texte, die Texte von Zeit Online weisen nun eine höhere Negativität auf. Das ist ein recht stark anderes Ergebnis als zuvor.
14. Januar 2026
Beim überwachten maschinellen Lernen (auch supervised machine learning SML) geht es darum, das ein Algorithmus basierend auf codierten Beispieltexten statistische Muster in Texten erkennt. Dieses erlernte Wissen kann dann auf weitere Texte, die nicht codiert sind, angewandt werden. Der Kern dieses Verfahrens gleicht in weiten Teilen der klassischen manuellen Inhaltsanalyse. Relevante Teile dessen, was heute vorgestellt wird, habt ihr also bereits gemacht. Es gibt aber einen Entscheidenden unterschied: Dieses Verfahren lässt sich, ähnlich wie das lexikonbasierte Verfahren, aber im Gegensatz zur manuellen Inhaltsnalayse leicht auf mehrere Millionen Texte skalieren.
Konzeptionell kann man sich das wie folgt vorstellen. Der Computer hat noch nie eine Katze gesehen. Ihr zeigt ihm nun 20 Bilder von Katzen und sagt ihm, dass es sich hierbei um eine Katze handelt. Basierend auf diesen 20 Fotos lernt der Computer nun was eine Katze ist und kann in Zukunft eingeständig Katzen erkennen. (Tatsächlich lernt der Computer nicht, was eine Katze ist, sondern lernt nur, statistische Muster in den Bildern, die häufig mit dem Label Katze zusammen auftreten).
Zentral hierbei ist, dass grössere Mengen an zuverlässig codierten Beispielen existieren, die der Computer nutzen kann, um die Muster valide und reliabel zu erkennen. Da der Algorithmus auf den Beispielen quasi trainiert wird, nennt man diese Daten auch Trainingsdaten.
Bei den Trainingsdaten handelt es sich um einen Ausschnitt aus euren Gesamtdaten. Stellt euch folgendes Szenario vor: Ihr habt mehrere Millionen Social Media Posts zu einem Thema (z.B. Politik oder zu einem Produkt) und wollt analysieren, welche davon positiv, neutral oder negativ sind. Händisch wäre das nicht leistbar. Für SML nehmen wir nun wenige Tausend dieser Social Media Posts (z.B. eine Zufallsauswahl der Gesamtstichprobe) und nutzen diese Teilmenge unserer Gesamtdaten. Um den Computer nun aber zu trainieren, müssen wir die Texte dieser Teilmenge in die gewünschten Kategorien codieren (auch: labeln). Wir müssen dem Computer schliesslich erstmal beibringen, bei welchem Text es sich um einen negativen oder einen positiven Text handelt.
Wir entwickeln nun also ein Codebuch und codieren alle Texte händisch in die gewünschten Kategorien. Das haben wir schon gelernt und entspricht soweit erstmal der klassischen Inhaltsanalyse. Wenn wir jeden Text zuverlässig in negativ, neutral und positiv unterteilt haben, können wir dem Computer unsere Ergebnisse zeigen. Dieser lernt dann die Muster zwischen den Texten und ihren Labels und kann dann - idealerweise - zukünftig eigenständig und zuverlässig bei den restlichen Social Media Posts einschätzen, ob diese positiv, neutral oder negativ sind.
Wichtig dabei ist auch, dass wir dem Algorithmus nicht nur zeigen was wir wollen, sondern auch zeigen, was wir nicht wollen. In unserem Katzenbeispiel wäre es z.B. sinnvoll, dem Computer auch Bilder von Hunden zu zeigen, damit er besser lernt, zwischen Hunden und Katzen zu unterscheiden; die sehen sich ja zumindest sehr ähnlich. In unserem Beispiel mit den Social Media Posts: Es könnte ja sein, dass euer Chef nur an negativen Kommentaren zu eurem Produkt interessiert ist, er will schliesslich wissen, was er besser machen kann. Es wäre jetzt allerdings nicht sinnvoll, dem Algorithmus nur negative Kommentare zu zeigen. Vielmehr wäre die Präzision zur Erkennung von negativen Kommentaren viel höher, wenn ihr ihm auch neutrale und positive Kommentare beibringt.
Wir könnten dafür auch ein lexikonbasiertes Verfahren nutzen. Allerdings hatten wir ja gelernt, dass diese Verfahren recht eingeschränkte Validität besitzen. SML erzielt hier häufig bessere Ergebnisse, da das Verfahren des “Lernens” auch komplexere Muster erkennen kann, die ein Lexikon an und über seine Grenzen bringt.
Aber auch SML kommt mit Nachteilen. Zum einen erfordert es oft eine grossere Menge manuell codierter Trainingsdaten. Genau wie das Erstellen eines guten Lexikons kann das sehr zeitaufwendig sein. Zum anderen ist das Modell immer maximal so gut wie die menschlische Codierung der Trainingsdaten, auf denen das Modell/der Algorithmus beruht. Wenn die Trainingsdaten eine geringe Qualität haben, also z.B. sehr unzuverlässig codiert wurden, kann der Algorithmus keine klaren Muster erlernen und hat dann (ebenso) nur eine geringe Validität*. Genauso kann es sein, dass die Anzahl an Trainingstexten noch nicht ausreicht, dass der Algorithmus die Muster zuverlässig gelernt hat. Zuletzt kann es aber auch sein, dass der Algorithmus auch bei perfekten Trainingsdaten noch (zu) viele Fehler macht. Um das zu prüfen, muss der Algorithmus stets auf seine Güte getestet werden. Wie immer ist das ein sehr zentraler Punkt, wir gehen am Ende auf ihn ein.
*Validität ist auch beim Supervised Machine Learning primär eine theoretische Frage. Sie bezieht sich darauf, ob die gewählten Kategorien/Konstrukte sinnvoll sind und ob sie angemessen operationalisiert wurden (Labels, Codierregeln, Trainingsdaten). Algorithmische Performance (z.B. F1) zahlt unterstützend (oder beeinträchtigend) auf Validität ein, ist aber keine hinreichende Bedingung für Validität.
Wichtig Vorweg, um Entäuschungen zu vermeiden. Für ein robustes, d.h. gut funktionierendes SML braucht man meist mindestens mehrere hundert, oft tausend Texte als Trainingsbasis. In euren Daten habt ihr dafür nicht genug. In aller Regel wird die Analyse daher bei euch nicht gut funktionieren. Da wir hier in einem Lernsetting sind, ist das für eure Seminararbeit gar kein Problem! Ihr sollt nur wissen, wie ihr das Verfahren prinzipiell anwendet. Das ist aber der Grund, warum ich SML für euch und eure Seminararbeit nicht empfehle. Es reicht aus, wenn ihr ein Lexikonbasierten Ansatz nutzt.
Hier will ich es euch allerdings gerne “richtig” zeigen und dafür nutzen wir einen grossen Datensatz. Wir arbeiten also nicht mit dem bisherigen Datensatz, der ja auch nur aus 15 Texten bestand, sondern nutzen Daten, die schon verfügbar sind. Konkret nutzen wir einen Datensatz, in dem 2000 Film-Bewertungen gesammelt sind. Dieser Datensatz ist bei Quanteda schon integriert, bzw. in einem Schwester-Paket von quanteda, das wir zunächst auf die bekannte Art laden müssen.
#install.packages("quanteda.textmodels")
library(quanteda.textmodels)Warning: Paket 'quanteda.textmodels' wurde unter R Version 4.5.2 erstelltlibrary(quanteda)Jetzt können wir den gewünschten Datensatz einlesen. Dieser heisst data_corpus_moviereviews und wir weisen ihn dem Object data_movie zu, welches rechts in unserem environment dann auftaucht.
data_movie <- data_corpus_moviereviewsPer data(package = "quanteda") oder data(package = "quanteda.textmodels") können wir übrigens sehen, welche sonstigen Daten in den beiden Paketen enthalten sind.
Wenn wir uns als nächstes unsere Daten anschauen, sehen wir, dass das Format etwas komisch bzw. ungewohnt ist. Es liegt nicht als gewohnte Tabelle vor. Wenn wir summary() nutzen, bekommen wir trotzdem einen Überblick. Wir sehen jetzt, dass die Texte in einzelnen Dateien liegen, ansonsten sieht es schon recht vertraut aus. Mit einem einfachen Befehl, bekommen wir bei quanteda die Texte aber auch wieder direkt in die Tabelle, wie wir es bereits aus unserem kleinen Beispieldatensatz kennen.
data_movieCorpus consisting of 2,000 documents and 3 docvars.
cv000_29416.txt :
"plot : two teen couples go to a church party , drink and the..."
cv001_19502.txt :
"the happy bastard's quick movie review damn that y2k bug . ..."
cv002_17424.txt :
"it is movies like these that make a jaded movie viewer thank..."
cv003_12683.txt :
" " quest for camelot " is warner bros . ' first feature-leng..."
cv004_12641.txt :
"synopsis : a mentally unstable man undergoing psychotherapy ..."
cv005_29357.txt :
"capsule : in 2176 on the planet mars police taking into cust..."
[ reached max_ndoc ... 1,994 more documents ]summary(data_movie)[1:5,] #zeigt nur die ersten 5 Zeilen an Text Types Tokens Sentences sentiment id1 id2
1 cv000_29416.txt 354 841 9 neg cv000 29416
2 cv001_19502.txt 156 278 1 neg cv001 19502
3 cv002_17424.txt 276 553 3 neg cv002 17424
4 cv003_12683.txt 314 558 2 neg cv003 12683
5 cv004_12641.txt 380 841 2 neg cv004 12641data <- convert(data_movie, to = "data.frame")
View(data)Wir sehen hier jetzt die Texte in der entsprechenden Spalte und das zugeordnete Sentiment, entweder pos oder neg in der nächsten Spalte. Die Spalten “doc_id” und “id1” sowie “id2” sind lediglich Zeilen zur Identfikation und für uns nicht zentral.
Wichtig ist, dass wir nun davon ausgehen, dass die angebenen Sentiments das finale Urteil von menschlichen Codierern sind. Das heisst, wir befinden uns jetzt bereits an einem Zeitpunkt, wo das Codebuch und die Codierung der Texte durch mehrere Menschen bereits stattgefunden hat. Zudem wurde die Intercoder-Reliabilität bestimmt (und für gut befunden) und - falls es Widersprüche in den Wertungen der einzelnen Codierer gab - die finale Wertung für jeden Text festgelegt. Diese finale Wertung ist in der Spalte “sentiment” als “pos” or “neg” festgehalten. 1000 Texte haben das Sentiment “pos” und 1000 das Sentiment “neg”. Diese Wertungen sind unser Gold-Standard, der Massstab, anhand dessen wir den Computer und dessen automatische Kategorisierungen messen.
table(data$sentiment) #wir sehen, es sind tatsächlich je 1000 Texte
neg pos
1000 1000 Ausserdem ist wichtig zu verstehen, dass die 2000 codierten Texte die jetzt in diesem Datensatz sind in der Realität nicht alle unsere Daten sind. Das sind nur die Daten, die wir händisch codiert haben und dafür nutzen, einen Algorithmus zu trainieren, der dann für alle ähnlichen Probleme nutzbar ist. Das heisst, wir nutzen diese 2000 Texte um damit in Zukunft viel viel grössere Datensätze zu klassifizieren. Hier sind es ja beispielsweise Rezensionen zu Filmen. Wenn wir aber wieder in unserem Beispiel mit den Social Media Posts sind, ist gut vorstellbar, dass eine Firma viele tausende Kommentare erhalten hat. Auch in diesem Fall würdet ihr euren Algorithmus auf einer verhältnismässig kleinen Menge an Texten trainieren, die ihr vorher händisch codiert habt. Wenn das passiert ist und gut funktioniert hat, könnt ihr dann in der Folge kinderleicht alle anderen tausende Posts klassifizieren; das müsst ihr dann nicht mehr per Hand machen und genau dafür ist automatisierte Inhaltsanalyse da. Sie erlaubt es gigantische Textmengen analysieren zu können.
Damit das passiert, also der Computer die Texte automatisiert (in diesem Beispiel) in negativ und positiv einordnen kann, müssen wir ihn trainieren. Während des Trainings lernt er was er machen soll, für welche Zuordnungen er in den Texten Muster erkennen soll. Hierfür verwenden wir allerdings nicht alle Texte. Ein paar Texte behalten wir aussen vor, damit wir nach den Computer nach dem Training auch richtig testen können. Wenn wir ihm alle Texte zum Training geben, hat er auch die Testfälle schon gesehen und kennt die Lösung schon. Das wäre in etwa so, wie wenn ihr beim Lernen für eine Matheklausur nicht nur Altklausuren bekommt, sondern auch die tatsächliche neue Klausur bereits mit erhaltet. Das würde natürlich das Ergebnis bei der Klausur dann massiv verfälschen. Gelernt wird also auf einem Großteil der Daten, meist 70% oder 80%. Die restlichen Daten werden zum Testen zurück gehalten, wir brauchen sie später nochmal.
set.seed(1) #googelt mal, wenn euch interessiert, was dieser Befehl bewirkt und warum wir ihn nutzen
library(dplyr) #für die folgenden zwei Befehle, benötigen wir dieses Paket
train <- data %>% slice_sample(prop = 0.8)
test <- anti_join(data, train)Joining with `by = join_by(doc_id, text, sentiment, id1, id2)`Wir haben nur 80% der Texte aus data randomisiert dem Objekt train zugewiesen. In der letzten Zeile haben wir alle übrigens Texte dem Objekt test zugewiesen.
Jetzt wollen wir die Texte vorbearbeiten (meist preprocessing genannt). Diesen Schritt kennen wir bereits in Grundzügen. Hier können Stopwords entfernt werden, Punkte und andere Dinge, die uns in der Regel nicht interessieren. Hier ist diese Vorbearbeitung aus zwei Gründen wichtiger als bisher. Da die Abläufe komplexer sind und es daher bei vielen Texten teilweise recht lange dauern kann, sparen wir Zeit, wenn wir unnötige Informationen entfernen. Zudem wird die Qualität und Güte der Klassifikation oft (aber nicht immer) gesteigert, wenn die Daten vereinfacht bzw. auf das Wesentliche reduziert sind.
Die Code in R hierfür ist wie recht weit am Anfang in diesem Tutorial.
toks_train <- tokens(
train$text,
remove_punct = TRUE,
remove_numbers = TRUE
) |>
tokens_tolower() |>
tokens_remove(stopwords("en"))Wir haben hier fünf Dinge gemacht. Wir haben alle Punktierungen entfernt, wir haben alle Zahlen entfernt, wir haben alle Wörter klein geschrieben und wir haben alle Stopwords entfernt. Da die Texte auf Englisch sind, haben wir hier natürlich auch die englischen Stopwords entfernt. Ausserdem haben wir ganz generell die Texte in einzelne Wörter, Tokens, ausgesplittet. Diese Wörter oder Tokens sind die Arbeitsgrundlage. Auch das wissen wir bereits von früheren Einheiten.
Wichtig Damit die Validierung später korrekt stattfinden kann, d.h. ob das Training gut funktioniert hat, müssen die Testdaten in identischer Weise vorbereitet werden wie die Trainingsdaten.Sonst ist der Vergleich nicht mehr gegeben. Wir machen daher genau das gleiche nochmal für die Testdaten.
toks_test <- tokens(
test$text,
remove_punct = TRUE,
remove_numbers = TRUE
) |>
tokens_tolower() |>
tokens_remove(stopwords("en"))Als nächstes werden diese Daten (wieder sowohl train als auch test) nun in ein effizientes Format gebracht, mit dem der Computer gut rechnen kann: Matrizen. Auch das kennen wir bereits. Tokens (also meist Wörter) werden hier Features genannt.
dfm_train <- dfm(toks_train)
dfm_test <- dfm(toks_test)
dfm_testDocument-feature matrix of: 400 documents, 22,062 features (98.77% sparse) and 0 docvars.
features
docs happy bastard's quick movie review damn y2k bug got head
text1 1 1 1 5 1 1 1 1 1 1
text2 0 0 1 2 0 0 0 0 0 0
text3 0 0 0 0 0 0 0 0 0 0
text4 0 0 0 2 0 0 0 0 0 0
text5 0 0 0 7 0 0 0 0 1 0
text6 1 0 0 2 0 0 0 0 0 0
[ reached max_ndoc ... 394 more documents, reached max_nfeat ... 22,052 more features ]Nun wird nochmal weiter versucht, unnötige Informationen zu entfernen, um den anschliessenden Trainingsprozess effizienter und idealerweise besser zu gestalten. Hier können wir z.B. Wörter entfernen, die nur in wenigen oder in fast allen Texten vorkommen (diese Wörter sind dann nicht sehr informativ). Als Erinnerung: Wir versuchen ja Texte in positives und in negatives Sentiment zu unterscheiden. Genau wie “und”, das vermutlich in beiden Klassen vorkommt, sind sehr selten und sehr häufige Wörter nicht informativ um uns bei der Unterscheidung zu helfen.
Ein weiteres, sehr beliebtes, Verfahren ist auch die Gewichtung von Features. Hier ist TF-IDF (Term Frequency - Inverse Document Frequency) ein bekanntes Verfahren. TF–IDF gewichtet Wörter so, dass häufige, aber wenig informative Wörter abgewertet und seltene, für einzelne Dokumente charakteristische Wörter aufgewertet werden. Je nach Algorithmus, erhöht das sehr oft die Güte eines Klassifikationsmodells. Trimming entfernt Wörter, TF-IDF gewichtet Wörter.
Abschliessend wird der Feature-Raum der Test-Daten noch auf den Feature-Raum der Trainingsdaten limitiert. Da das Modell nur die Wörter (d.h. Features) aus den Trainingsdaten kennt, sind weitere andere Features ohne Mehrwert.
dfm_train <- dfm_trim(dfm_train, min_docfreq = 5) #Wir behalten nur Wörter, die in mind. 5 Texten vorkommen
dfm_train <- dfm_tfidf(dfm_train) #tfidf anwenden
dfm_test <- dfm_match(dfm_test, featnames(dfm_train))Jetzt sind die Vorbereitungen abgeschlossen und wir können mit dem tatsächlichen Training beginnen. Zunächst muss dafür ein Modell gewählt werden. Es gibt viele verschiedene Algorithmen, die auf unterschiedlichen mathematischen Verfahren basieren und entsprechend verschiedene Anwendungsfälle und Vor- und Nachteile haben. Also Sozialwissenschaftlerinnen reicht oft ein grobes Verständnis, sich an der Literatur zu orientieren und/oder verschiedene Modelle auszuprobieren, und zu schauen, welche die besten Resultate erbringen. Wir fokussieren uns auf drei Verfahren:
Die ersten beiden Modelle sind in dem Paket quanteda.textmodels enthalten, das haben wir bereits geladen. Für SVM müssen wir ein weiteres Paket laden. Wie so oft geht der Kern des Verfahrens, in dem Fall das Training, sehr schnell bzw. benötigt sehr wenige Zeilen Code. Die folgenden Code Zeilen laden die benötigten Pakete und trainigen die jeweiligen Algorithmen basierend auf den Trainingsdaten.
#install.packages("e1071")
library(e1071)Warning: Paket 'e1071' wurde unter R Version 4.5.2 erstellt#Naive Bayes
model_nb <- textmodel_nb(dfm_train, train$sentiment)
#Logistische Regression
model_lr <- textmodel_lr(
dfm_train,
train$sentiment)
#SVM
x_train <- as.matrix(dfm_train) #SVM braucht Daten nochmal in einem anderen Format
x_test <- as.matrix(dfm_test)
model_svm <- svm( #dieser Prozess dauert einige Sekunden
x = x_train,
y = train$sentiment,
kernel = "linear",
cost = 1,
scale = FALSE
)Jetzt haben wir mit wenig Code bereits drei ganz unterschiedliche Modelle trainiert. Dabei wurden jeweils nur die Trainingsdaten verwendet. Als nächstes wollen wir testen, wie gut das Training funktioniert hat. Dazu wenden wir unsere trainierten Modelle auf unsere Testdaten an, die dafür zurück gehalten wurden.
#Naive Bayes
pred_nb <- predict(model_nb, dfm_test)
#Logistische Regression
pred_lr <- predict(model_lr, dfm_test)
#SVM
pred_svm <- predict(model_svm, x_test)Im letzten Schritt wollen wir nun schauen, wie die jeweiligen Modelle abgeschnitten haben. Hierfür ist nochmal wichtig, sich klar zu machen, was eigentlich unser Ziel ist. Wir haben Texte, die wir in “positives” und “negatives” Sentiment unterscheiden wollen. Es gibt daher vier Fälle wie eine Klassifikation ausfallen kann. Sie kann auf zwei Arten richtig sein und auf zwei Arten falsch. Die richtigen beiden Fälle wären, wenn das Modell “positive” Texte korrekt als solche identifiziert und genauso “negative” Texte korrekt aus negative. Die umgekehrte Logik gilt für die fehlerhaften Klassifizierungen: falsch ist, wenn “positive” Texte als negativ und “negative” Texte als positiv klassifiziert werden. Wir können uns das einmal anschauen, wie die Ergebnisse für das erste Modell aussehen. Das geht wie folgt:
cm_nb <- table(Klassifikation = pred_nb, Tatsächlich = test$sentiment)
cm_nb Tatsächlich
Klassifikation neg pos
neg 169 49
pos 23 159Wir sehen hier eine sogenannte Confusion-Matrix (Kontingenztafel). In ihr wird angezeigt, wie die tatsächlichen Werte von dem Algorithmus klassifiziert wurden. Wir sehen dass in 169 Fällen Texte, die tatsächlich (also gemäss unserem manuell codierten Gold-Standard) negativ sind, von dem Modell auch korrekt als negativ eingestuft wurden. Bei 23 anderen Texten, die eigentlich tatsächlich auch negativ sind, hat das Modell fälschlicherweise eine Einstufung als positiv gemacht. Für die Fälle, die tatsächlich positiv sind, hat das Modell für 159 Texte korrekt entschieden, dass sie positiv sind. In 49 Fällen hat es hier einen Fehler gemacht und die eigentlich positiven Texte als negativ klassifiziert. Für die Texte, die tatsächlich positiv sind, werden also mehr Fehler gemacht. Oder anders rum, das Modell hat eine Tendenz, Texte als negativ zu klassifizieren.
Schauen wir uns an, wie die beiden anderen Modelle abgeschnitten haben.
cm_lr <- table(Klassifikation = pred_lr, Tatsächlich = test$sentiment)
cm_lr Tatsächlich
Klassifikation neg pos
neg 150 29
pos 42 179Hier erkennen wir dass das Modell etwas mehr Fehler bei den Texten macht, die tatsächlich negativ sind. Oder auch wieder anders ausgedrückt, das Modell hat eine Tendenz, Texte als positiv zu klassifizieren. Zuletzt schauen wir uns die Ergebnisse von SVM an.
cm_svm <- table(Klassifikation = pred_svm, Tatsächlich = test$sentiment)
cm_svm Tatsächlich
Klassifikation neg pos
neg 166 32
pos 26 176Hier sehen wir insgesamt weniger Fehler und das Fehlerbild ist auch ausgeglichener. Um die Leistung der jeweiligen Modelle einfacher vergleichen zu können, gibt es verschiedene Metriken. Eine sehr einfache ist die Accuracy (Genauigkeit). Hier rechnet man schlicht: Anzahl der korrekten Vorhersagen / alle Vorhersagen. Also zum beispiel händisch für die unterste Confusion Matrix: (166+176)/400 = 0.855. Das geht auch per Code für alle drei Modelle:
#Naive Bayes
sum(diag(cm_nb)/sum(cm_nb))[1] 0.82#Logistic Regression
sum(diag(cm_lr)/sum(cm_lr))[1] 0.8225#SVM
sum(diag(cm_svm)/sum(cm_svm))[1] 0.855Accuracy ist aber oft kein guter Wert um die Leistung und Güte von Modellklassifikationen anzugeben. Wenn die Klassen gleich verteilt sind, hätte auch ein sehr sehr dummes Modell, dass immer die gleiche Antwort gibt, eine Accuracy von 50%. Wenn die Klassen nicht gleich verteilt sind, kann die Accuracy sogar deutlich höher liegen, obwohl das Modell quasi komplett unfähig ist. Denkt an die Erkennung von Spamemails. Es ist schon lange so, dass die meisten Emails Spam sind und von Spamfiltern ausgefiltert werden. Nehmen wir an, dass 90% aller Emails Spam sind und 10% echte und wichtige Emails. Wenn der Spamfilter ALLE Emails als Spam klassifizieren würde, hätte er eine Accuracy von 90%, was ja recht gut klingt, würde aber faktisch komplett nutzlos sein. Die richtige Wahl der Evaluationsmetrik ist daher sehr wichtig, da sie je nach Kontext komplett nichtssagend und irreführend sein könnte. Hier muss man genau aufpassen.
Auch die Unterscheidung der Fehler ist je nach Anwendungsfall sehr wichtig, da die beiden Fehler unterschiedlich relevant sein können. Stellt euch einen medizinischen Anwendungsfall vor, den ihr vermutlich gut kennt: Basierend auf einem Covid-Test entscheidet sich, ob jemand in Quarantäne muss. Wenn der Patient tatsächlich Covid hat, wollen wir das unbedingt wissen, damit der Patient isoliert werden kann und niemanden ansteckt. Hingegen ist es nicht sooo schlimm, wenn der andere Fehler unterläuft: Wenn jemand eigentlich kein Covid hat aber doch in Quarantäne muss. Das ist zwar unangenehm und nervig, im Zweifel aber nicht lebensbedrohlich. Das heisst, hier wäre es gut, wenn das Modell sehr sensitiv ist, das heisst, die Fälle die uns interessieren (in dem Fall Covid) auch zuverlässig erkennt. Je nach Anwendungsfall müsst ihr überlegen welche Fehler für euch gewichtiger sind und welche Metrik dann am relevantesten ist. Für viele binäre Klassifikationsprobleme sind Precision und Recall, beziehungsweise F1, das harmonische Mittel aus Precision und Recall, relevante Metriken. Mehr Informationen zu Grundlagen hierzu findet ihr hier. F1 Werte ab 0.8 gelten als brauchbar. Es gibt auch Pakete in R mit denen ihr eine ganze Reihe von Metriken direkt ausrechnen. Zum Beispiel:
#install.packages("caret")
library(caret)Warning: Paket 'caret' wurde unter R Version 4.5.2 erstelltLade nötiges Paket: ggplot2Lade nötiges Paket: latticecm_svm <- confusionMatrix(pred_svm, test$sentiment)
cm_svm #gibt verschiedene MetrikenConfusion Matrix and Statistics
Reference
Prediction neg pos
neg 166 32
pos 26 176
Accuracy : 0.855
95% CI : (0.8166, 0.888)
No Information Rate : 0.52
P-Value [Acc > NIR] : <2e-16
Kappa : 0.7099
Mcnemar's Test P-Value : 0.5115
Sensitivity : 0.8646
Specificity : 0.8462
Pos Pred Value : 0.8384
Neg Pred Value : 0.8713
Prevalence : 0.4800
Detection Rate : 0.4150
Detection Prevalence : 0.4950
Balanced Accuracy : 0.8554
'Positive' Class : neg
cm_svm$byClass["F1"] #gibt F1 F1
0.8512821 Damit sind wir am Ende der Analyse. Wie wir sehen, haben wir ein gutes Ergebnis erzielt und könnten das Modell bzw. den Algorithmus, den wir trainiert nun auch auf Filmrezensionen anwenden, um diese in positives oder negatives Sentiment zu klassifizieren.
Neue Texte, die durch den trainierten Algorithmus klassifiziert werden sollen, müssen in gleicher Weise vorverarbeitet werden wie die Trainings- und Testdaten. Dazu gehören Tokenisierung, Entfernung von Satzzeichen und ggf. Stoppwörtern, die Darstellung als Dokument-Feature-Matrix sowie – falls verwendet – Trimming und die Projektion auf den durch die Trainingsdaten definierten Feature-Raum. Anschließend kann das trainierte Modell auf diese Daten angewandt werden, z.B. pred_new <- predict(model_nb, dfm_neue_texte) In pred_new sind dann die Klassifikationen gemäss dem Modell enthalten.
Das Verfahren, das ich euch heute vorgestellt habe, ist eine sehr vereinfachte Darstellung des Ganzen. Hier noch ein paar kurze und rein konzeptionelle Anmerkungen die wichtig sind, um das ganze korrekt einordnen und verstehen zu können.
Wichtig: Im Zusammenhang von Klassifikationsaufgaben wird in Bezug auf die Resultate oft von True-Positives und False-Positives sowie True-Negatives und False-Negatives gesprochen. Eine Klasse, meist die, die uns mehr interessiert, wird dabei als positive bezeichnet. Das ist letztlich Definitionssache und kommt auf die Perspektive an. Bei der Spam-Erkennung wären die Spam-Emails unsere Positives, da wir diese entdecken und rausfiltern wollen. Bei der Covid-Analyse wäre der Fall “jemand hat Covid” der Positive Fall. (Achtung: Bei unserer Sentimentanalyse verwenden wir die Kategorien “positiv” und “negativ”. Das hat in dem Fall nichts miteinander zu tun uns ist sprachlicher Zufall. Wir könnten unsere zwei Kategorien auch “Äpfel” und “alles andere” nennen. In dem Fall wären unsere Äpfel die Klasse, die uns interessiert. Wenn ein Modell korrekt einen Apfel als Apfel identifiziert, würden wir von einem True-Positive sprechen).
Wichtig: Der motivierte Mensch könnte nun interessiert sein, die Performance der Modelle noch weiter zu erhöhen, was durchaus möglich ist. So könnte es sein, dass die Modelle besser funktionieren, wenn wir Stopwords nicht entfernen, oder wenn wir beim Trimming anders vorgehen und viele andere Möglichkeiten (siehe auch: Finetuning und n-grams). Allerdings können wir die Performance solcher nachträglich angepasster Modelle nicht mehr valide evaluieren, da keine unabhängigen Testdaten mehr zur Verfügung stehen. Würden wir das neue Modell auf den gleichen Testdaten validieren, würden wir sog. Overfitting riskieren. Das bedeutet, dass wir damit Gefahr laufen, das Training so lange zu optimieren, bis es ganz genau auf die zufälligen Besonderheiten unserer Testdaten passt, ohne dass damit aber eine Generalisierbarkeit des Modells gegeben ist. Das heisst, andere Daten könnten wir womöglich damit tatsächlich sogar schlechter vorhersagen als zuvor. Das würde die Validität unserer Analyse stark kompromittieren. Stellt euch auch hier wieder eine Klausurensituation vor. Wenn ihr die Lösungen nur auswendig lernt, seid ihr bei dieser spezifischen Klausur vermutlich wahnsinnig gut. Aber tatsächlich habt ihr kein wirkliches Verständnis erlernt und würdet bereits bei einer kleinen Variation oder einer anderen Klausur vermutlich sehr schlecht abschneiden. Es gibt allerdings Wege, dennoch mehr Spielraum zu haben um zu schauen, welche Spezifikationen und Preprocessing am geeignetesten ist. Das Stichwort hierfür ist Cross-Validation.
Wir wollen nun schauen, wie die beiden bereits behandelten Verfahren im Vergleich abschneiden. Die Performance des überwachten maschinellen Lernens haben wir ja eben ausgerechnet. Fehlt noch, wie das lexikonbasierte Verfahren einer Sentimentanalyse bei diesen Daten abschneidet.
Wir verwenden erneut das Sentiment-Lexikon, das bereits in Quanteda enthalten ist und wenden es auf unsere Testdaten an (da wir im lexikonbasierten Verfahren keine Trainingsdaten brauchen, könnten wir das Lexikon auch auf alle Texte anweden. Das würde aber die Vergleichbarkeit zu oben einschränken):
dfm_lex <- dfm(toks_test) |>
dfm_lookup(data_dictionary_LSD2015)
dfm_lexDocument-feature matrix of: 400 documents, 4 features (50.06% sparse) and 0 docvars.
features
docs negative positive neg_positive neg_negative
text1 13 7 0 0
text2 17 18 0 0
text3 35 21 0 0
text4 65 23 0 0
text5 37 25 0 0
text6 20 26 0 0
[ reached max_ndoc ... 394 more documents ]Was fällt uns auf, im Vergleich zur Klassifikation?
Bei der Klassifikation hatten wir direkt ein binäres Ergebnis: Ein Text war entweder “positive” oder “negative” vom Sentiment. Nun haben wir zwei Ergebnisspalten (bzw. vier, wenn man die Negationen mitberücksichtigt) und müssen das Ergebnis erstmal interpretieren bzw. abstrahieren, wenn wir es auf nur zwei Kategorien runterbrechen wollen.
Wichtig: das bedeutet nicht, dass das eine besser oder schlechter ist. Es sind unterschiedliche Verfahren, die unterschiedliches leisten; mit unterschiedlichen Stärken und Schwächen sowie Anwendungsgebieten.
Eine Möglichkeit wäre, die Texte als positiv zu klassifizieren, wenn die Anzahl der positiven Treffer, die der negativen übersteigt. Das ist aber nicht gottgegeben, sondern eine Entscheidung, die auch kritisiert werden kann. Andere Entscheidungen würden zu anderen Ergebnissen führen. Ausserdem, was passiert, wenn positive und negativ gleich ausgeprägt sind. Eine “neutral” Kategorie existiert in diesem Szenario nicht. (Beachtet ausserdem, dass ich die Negationen hier komplett missachte)
sentiment_score <- dfm_lex[, "positive"] - dfm_lex[, "negative"]
sentiment_lex <- ifelse(sentiment_score > 0, "pos", "neg")
sentiment_lex <- factor(sentiment_lex, levels = levels(test$sentiment)) #diese Zeile ist nur notwendig, damit die Daten für den nächsten Befehl im richtigen Format sind Hier habe ich jetzt festgelegt, dass Texte, die ausgeglichen sind, als “negative” gewertet werden. Das ist in dem Fall eine beliebige Entscheidung und wird die Ergebnisse wahrscheinlich beeinflussen (zumindest wenn es viele davon gibt). In so einem Fall sollte man in den Limitationen darauf hinweisen oder noch besser, auch die Alternative berechenn und schauen, ob sich die Endergebnisse stark unterscheiden.
In jedem Fall können wir nun aber auch hier eine Confusion-Matrix ausgeben lassen und gewünschte Metriken berechnen.
cm_lexikon <- confusionMatrix(sentiment_lex, test$sentiment)
cm_lexikonConfusion Matrix and Statistics
Reference
Prediction neg pos
neg 127 58
pos 65 150
Accuracy : 0.6925
95% CI : (0.6447, 0.7374)
No Information Rate : 0.52
P-Value [Acc > NIR] : 1.734e-12
Kappa : 0.3831
Mcnemar's Test P-Value : 0.5885
Sensitivity : 0.6615
Specificity : 0.7212
Pos Pred Value : 0.6865
Neg Pred Value : 0.6977
Prevalence : 0.4800
Detection Rate : 0.3175
Detection Prevalence : 0.4625
Balanced Accuracy : 0.6913
'Positive' Class : neg
cm_lexikon$byClass["F1"] F1
0.6737401 Wir sehen, dass unser lexikonbasierter Ansatz (mit den Schritten die wir danach gewählt haben) eine geringere Accuracy und auch einen geringeren F1 Score haben, als die Resultate, die auf unseren supervise machine learning Modellen basieren.